Earlier this year, I experimented with various LLM models using Ollama on our gaming PC with a Nvidia RTX 3070ti GPU. At the time, I had also tried with our other gaming PC running on an AMD Radeon 6750xt GPU. Unfortunately, I wasn’t successful and the models on that PC had fallen back to the CPU, resulting in running times at least 10x slower than the Nvidia GPU system.
Since then, enthusiasts online have filled in the support that AMD themselves can’t seem to deliver. Thanks to this Github project, it is now possible to run recent models on the 6750xt (aka gfx1031). Even more impressive, thanks to this Github project, I was able to rehabilitate my old Radeon RX590 (aka gfx803).
AMD Radeon 6750xt
This is an interesting card as it lacks the Nvidia CUDA support, but has 12 GB of VRAM rather than the 8 GB of the Nvidia card.
Installing Ollama
On this PC, I install apps and data on the larger D: drive, so first download OllamaSetup.exe and install via Powershell:
.\OllamaSetup.exe /DIR="D:\Program Files\Ollama"
Then quit Ollama from system tray and download the correct ROCM libraries for the 6750xt which is the gfx1031 generation.
- Find the rocblas.dll file and the rocblas/library folder within your Ollama installation folder (located at D:\Program Files\Ollama\lib\ollama\rocm).
- Delete the existing
rocblas/libraryfolder. - Replace it with the correct ROCm libraries.
- Set env var OLLAMA_MODELS=D:\Program Files\Ollama\models (create the folder)
- Then run Ollama again from Start menu.
Then launch OpenWebUI in Docker:
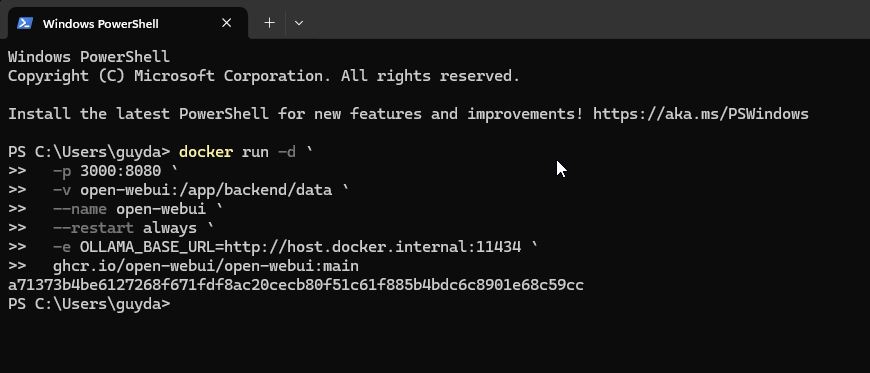
docker run -d `
-p 3000:8080 `
-v open-webui:/app/backend/data `
--name open-webui `
--restart always `
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 `
ghcr.io/open-webui/open-webui:main
Then browse to http://localhost:3000 to access OpenWebUI, where I tested the recent Qwen v3 model:
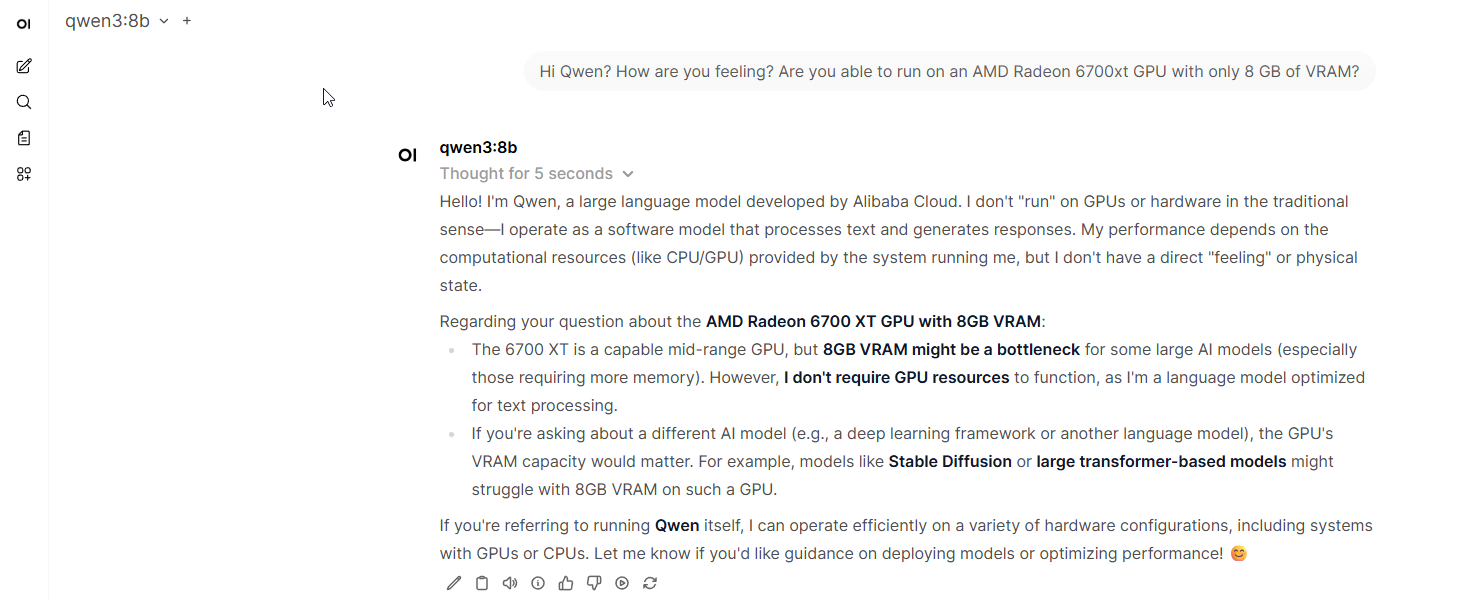
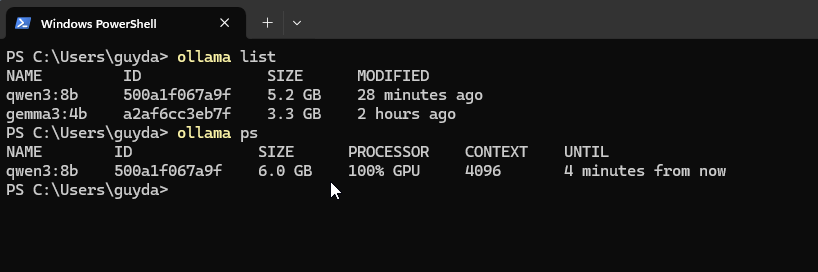
Monitoring the speed of the response, I was pleasantly surprised. Much faster than the CPU-fallback mode I experienced earlier. Ollama reported GPU being used:
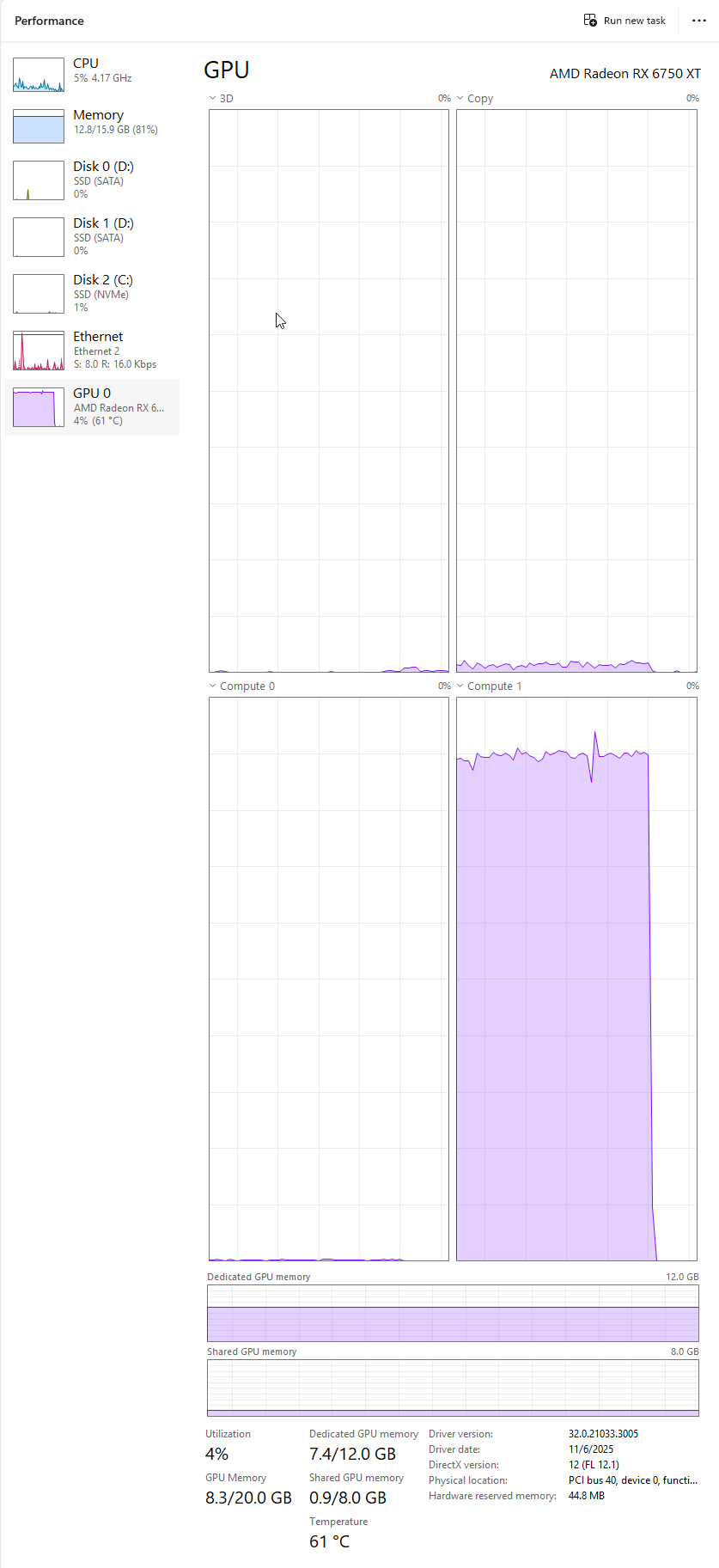
Monitoring the GPU usage via Task Manager, I was able to run queries against both Qwen and Gemma, though that is a bit too tight:
AMD Radeon RX 590
For an even bigger challenge, I decided to look at running Ollama using a AMD 590, nearly a decade old card now.
sudo docker run -it -d --restart unless-stopped --device=/dev/kfd --device=/dev/dri --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -p 8080:8080 -p 11434:11434 --name rocm64_ollama_095 robertrosenbusch/rocm6_gfx803_ollama:6.4.1_0.9.5 bash
sudo docker exec -ti rocm64_ollama_095 bash
./ollama pull gemma3:4b
./ollama pull qwen3:8b
python3 /llm-benchmark/benchmark.py
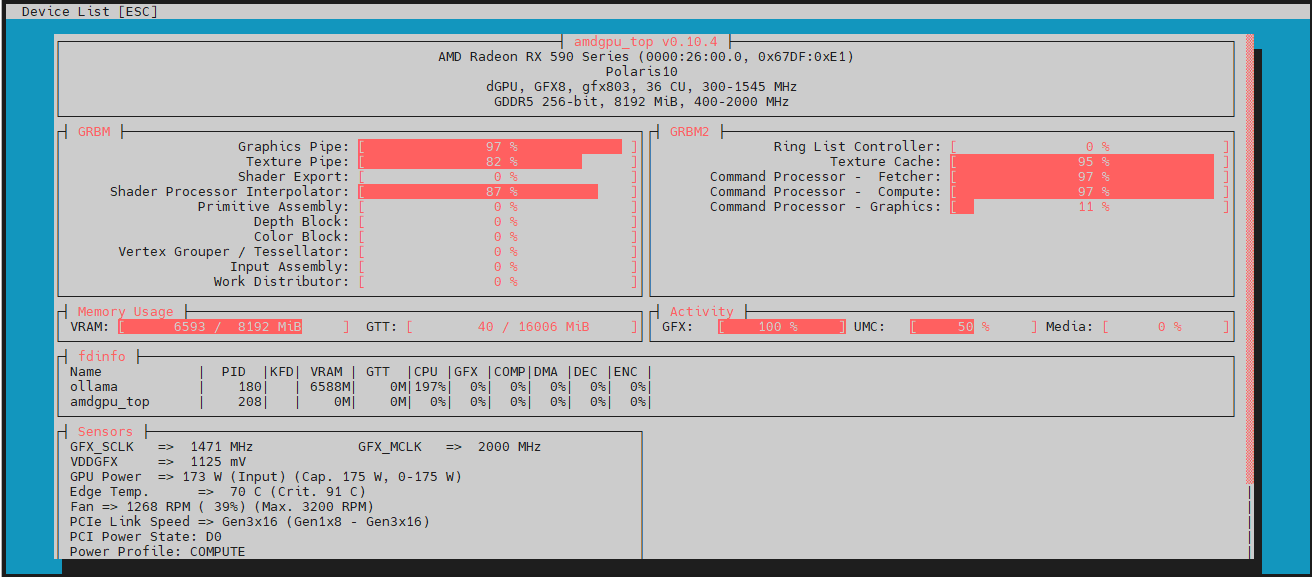
Then in another shell, I monitored the GPU usage with amdgpu_top, ensuring the old card was working as hard as it could:
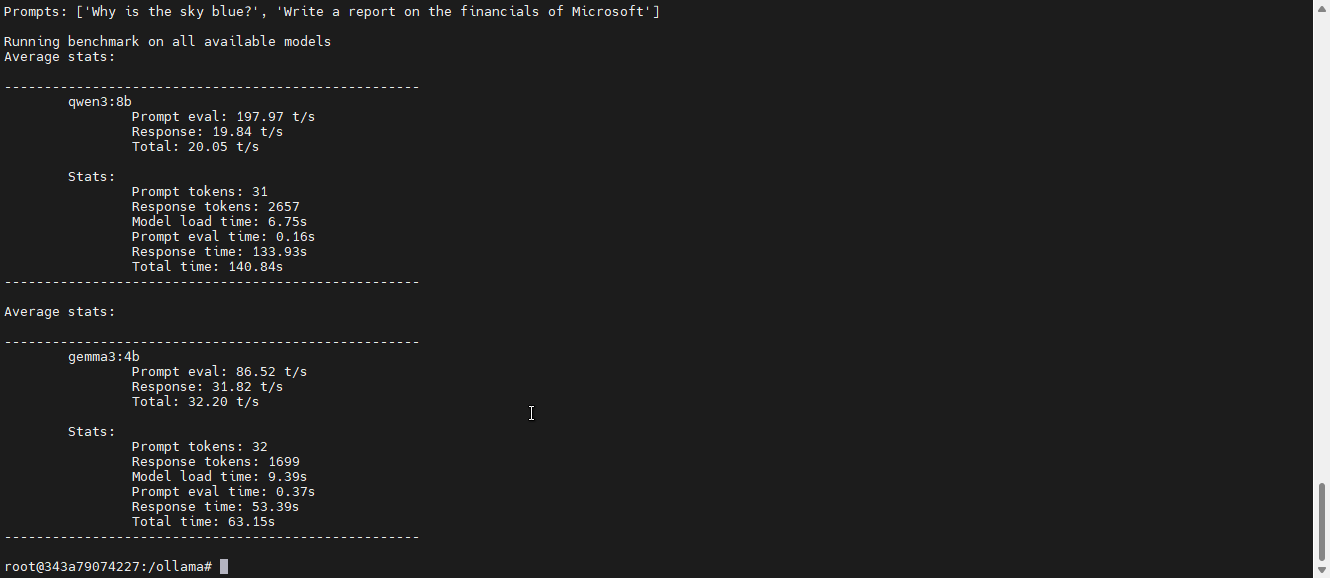
The results of the benchmark are not fast at all, but just impressive that these new models even run on hardware from a decade ago. Kudos to Robert Rosenbusch for his great work making this possible.
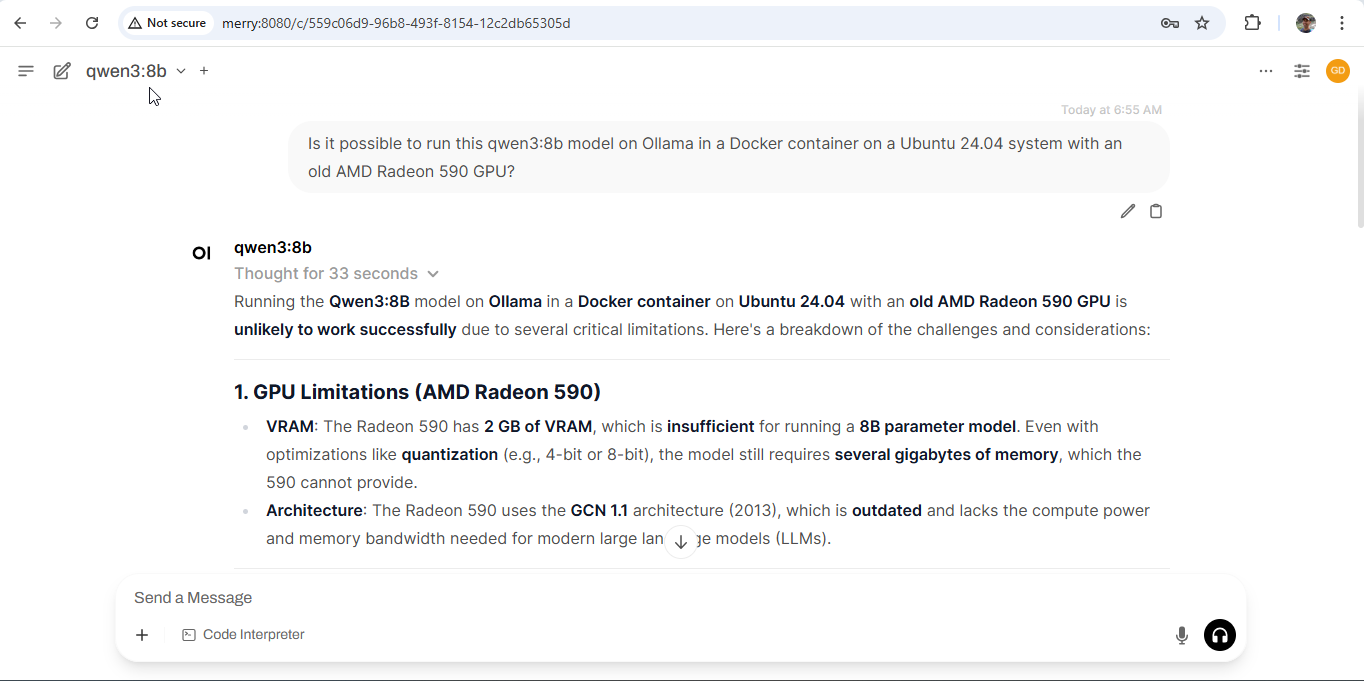
Finally, I browsed to the Ollama webui and asked the Qwen model if it thought I could run it on such an old AMD GPU. Quite rightly, Qwen advised me that it is highly unlikely it could run on such ancient hardware:
Network Hosting
With multiple systems on my home network hosting Ollama and different models now, I decided to put a single instance of OpenWebUI on the home server running 24/7 in the basement. This lets family members use local LLMs from anywhere on our home network, useful for comparisons against the public models like Gemini and ChatGPT.
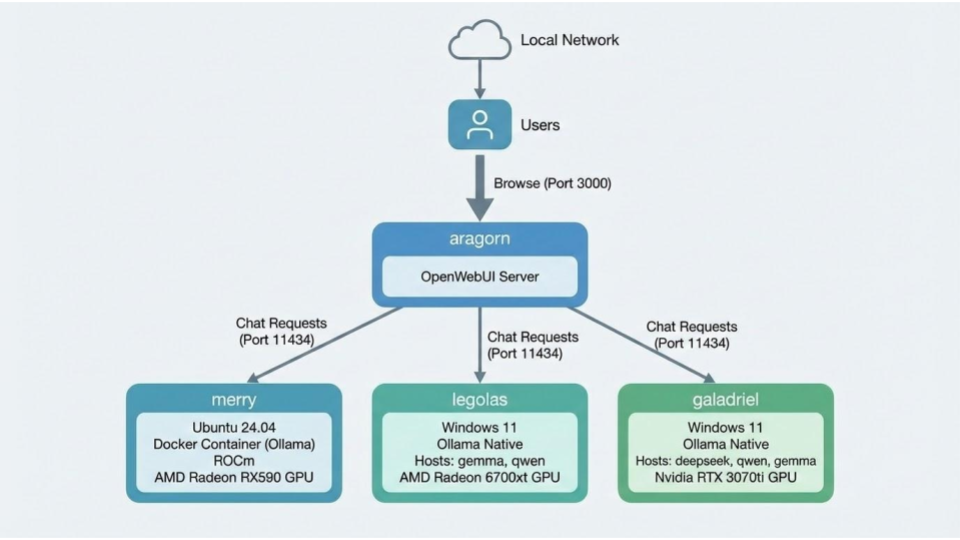
While the LLM frontend can expose different models on different computers, but it doesn’t do a good job of labelling them, dealing with certain workers being offline, nor selecting the fastest available worker. I am hopeful that OpenWebUI will improve handling of multiple Ollama workers in the future.
Benchmarking
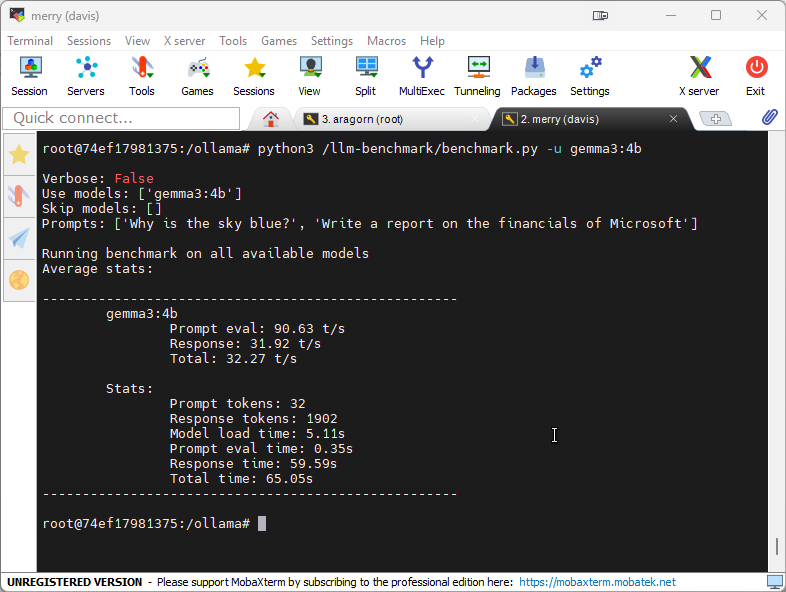
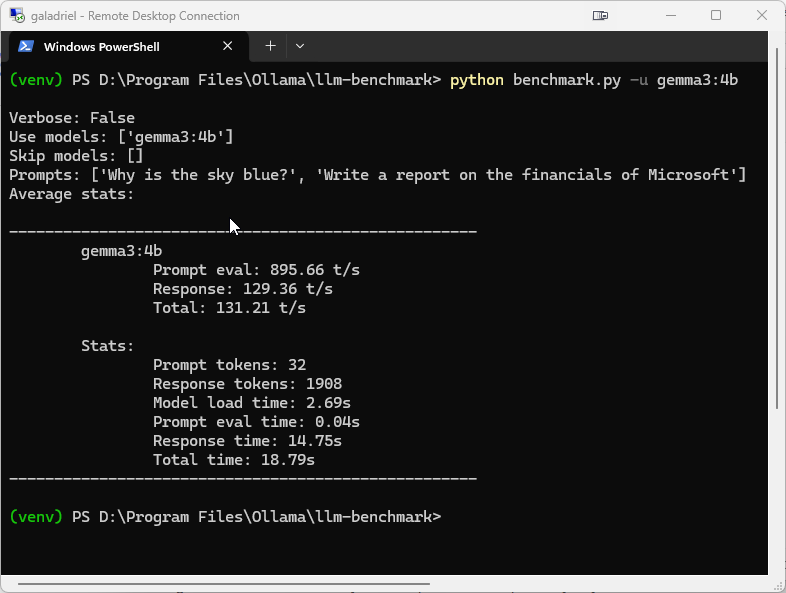
After forking and fixing a simple LLM benchmarking script, I deployed it to all 3 of my systems to see how well they ran the same prompts using the gemma3:4b as a common test.
Setup
First in Gitbash:
cd "d:/Program Files/Ollama"
git clone https://github.com/guydavis/llm-benchmark.git
cd llm-benchmark
python -m venv venv
Then in Powershell:
cd "d:\Program Files\Ollama\llm-benchmark"
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
.\venv\Scripts\activate
pip install -r requirements.txt
ollama list
python benchmark.py -u gemma3:4b
AMD Radeon RX 590
AMD Radeon 6750xt

Nvidia RTX 3070ti
Conclusions
Clearly, the open-weight models are rapidly improving if they can run reasonably on such old hardware. Soon these mid-weight LLMs will run on portable devices such as phones, improving upon the current embedded models. There is still clearly a serious performance penalty to run on an AMD GPU, instead of industry-standard Nvidia GPUs. Though simply being able to use AMD hardware is honestly a pleasant surprise.
With such progress happening, I fail to see why the American tech giants will be able to charge premium subscription prices. With the AI stock market boom in full swing right now, it will be interesting to see if they are still flying high in a year, in the face of open-weight model competition.
More in this series…
- Llama 3 - Llama 3
- Ollama - Ollama via OpenWebUI
- Deepseek - Trying small distills locally.
- Old Hardware - Running latest LLMs using old hardware (GPU and CPU)