So, I went looking for alternatives to Mint. After trying a number of paid services, I found them all to be wanting. I’m not interested in paying a monthly fee for “account disconnected from sync” errors every other day. If these services can’t sync reliably, I figured I’d try a self-hosted system, relying on an old-fashioned monthly import of a CSV-format export from my finacial instuitions.
Firefly III
Based on a Reddit discussion, I came across an open-source solution named Firefly III. There is Docker template for this application on the Unraid Community Apps, so I figured I’d give it a shot. My goal was to import and categorize transactions from my chequing, savings, and credit cards into Firefly accounts.
PostgreSQL
First, off Firefly requires a separate database. Not sure why an embedded database like SQLite couldn’t have been used by the author to simplfiy setup for new users, but this may be a planned technical hurdle to weed out users who would be better paying for a managed web service. Again the Community Apps section of my Unraid server made setting up a fresh Postgres database simple. The Firefly documentation doesn’t cover this database setup, but I’ve been using psql for many, many years now.
Data Importer
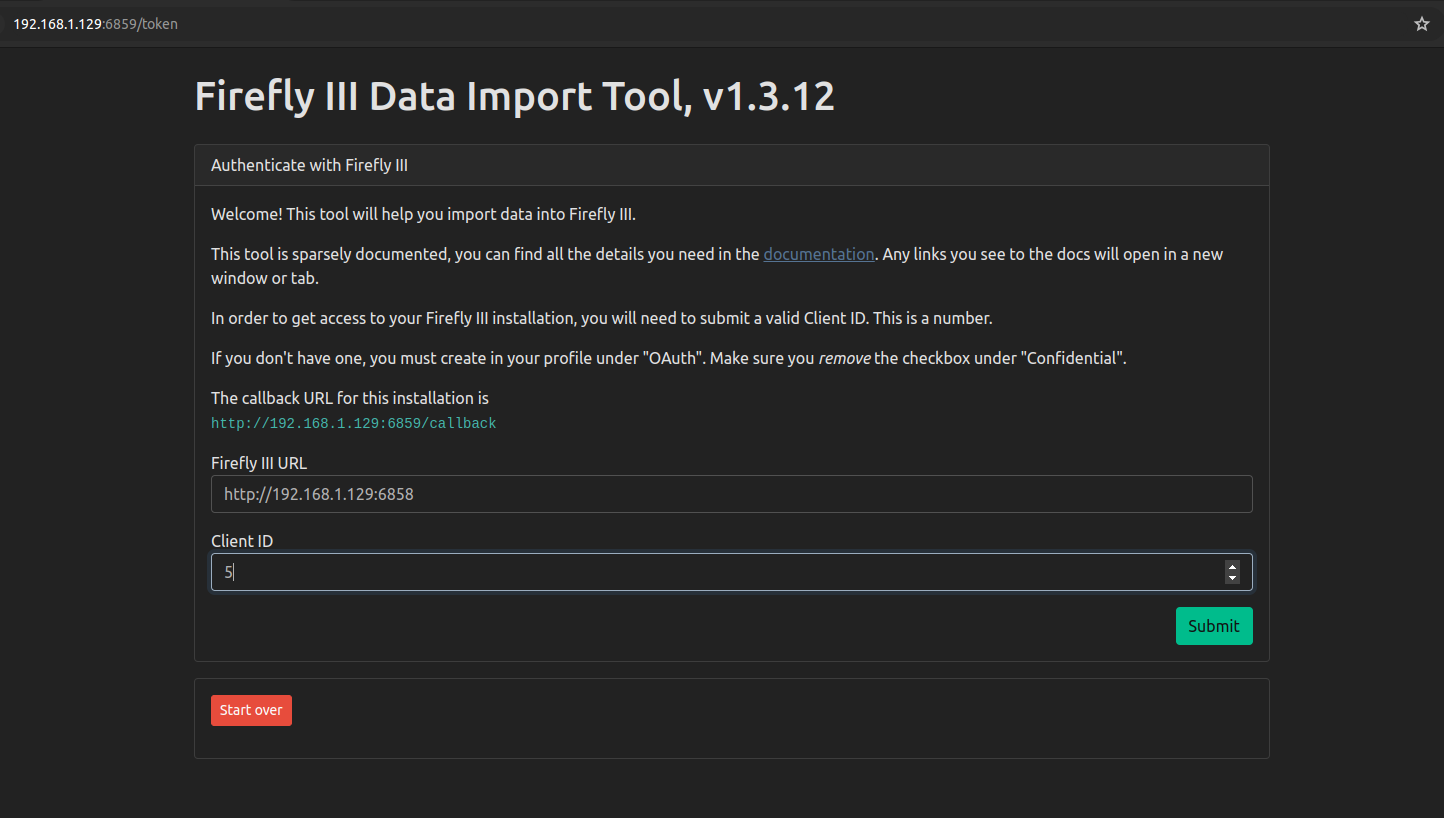
For reasons of “security”, Firefly has a completely separate Docker container that runs alongside the main Firefly container. To perform an import of CSV account data from my bank, I have carefully create OAuth credentials, carefully de-selecting a default option that will break the import process, which I learned digging through this app’s discussion forums.
Then I have to browse to another Console page entirely from the main Firefly WebUI. Then I enter the URI of the main WebUI and go through the import process.
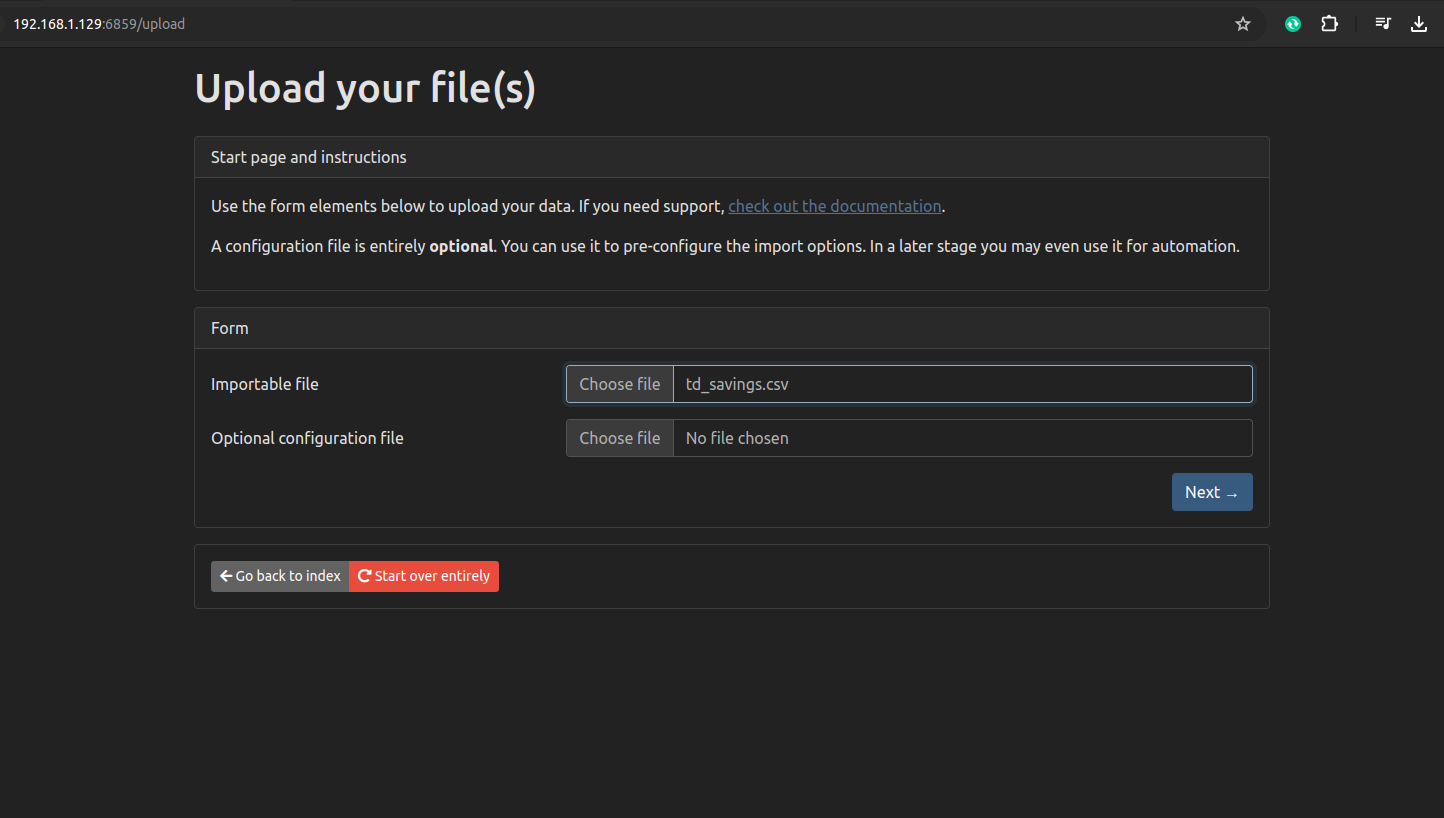
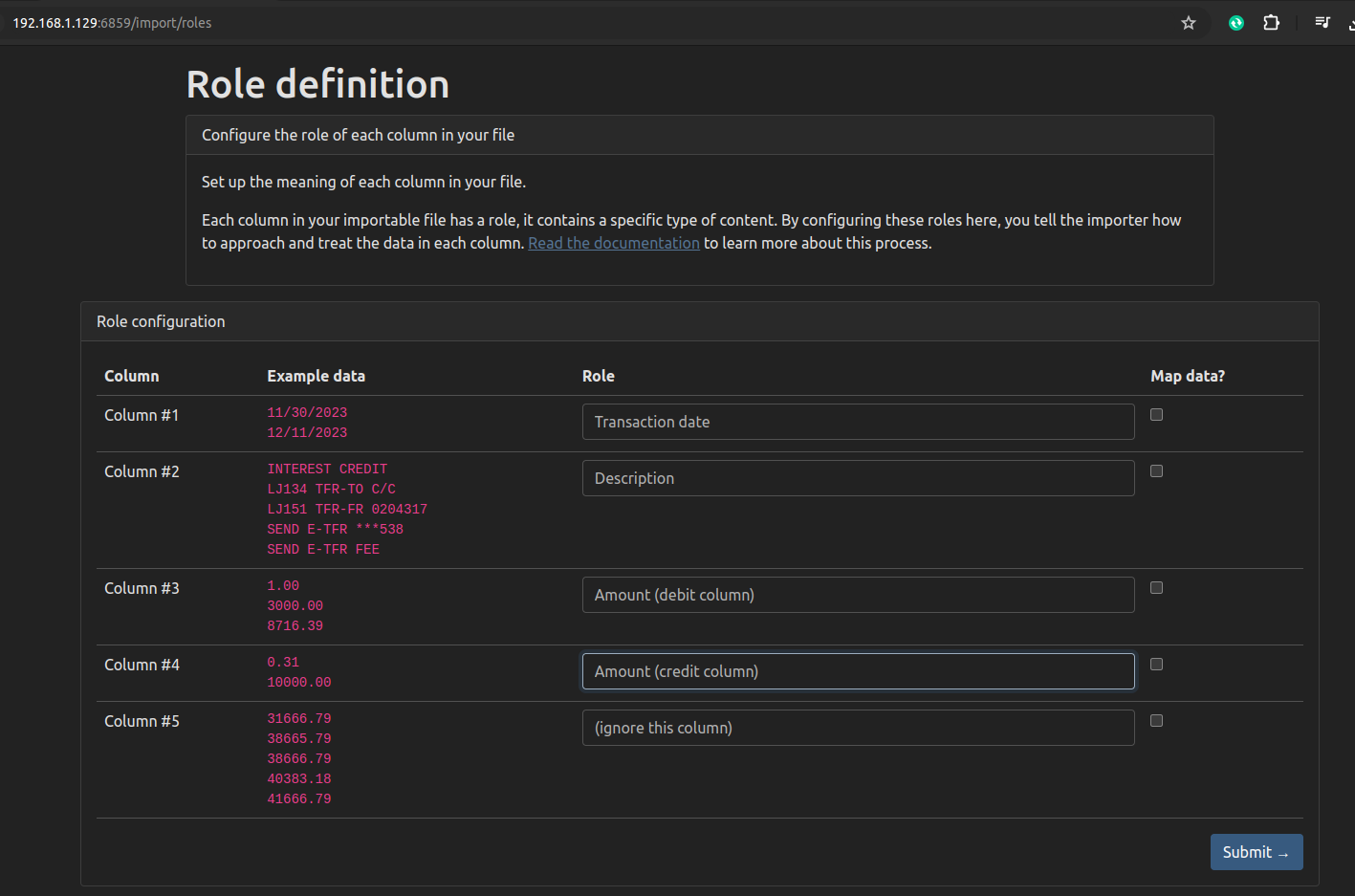
This screen was a bit finicky, so be careful about the choices you make here, depending on the exact format of your CSV. Picklist menus are not sorted alphabetically despite containing tens of menu items.
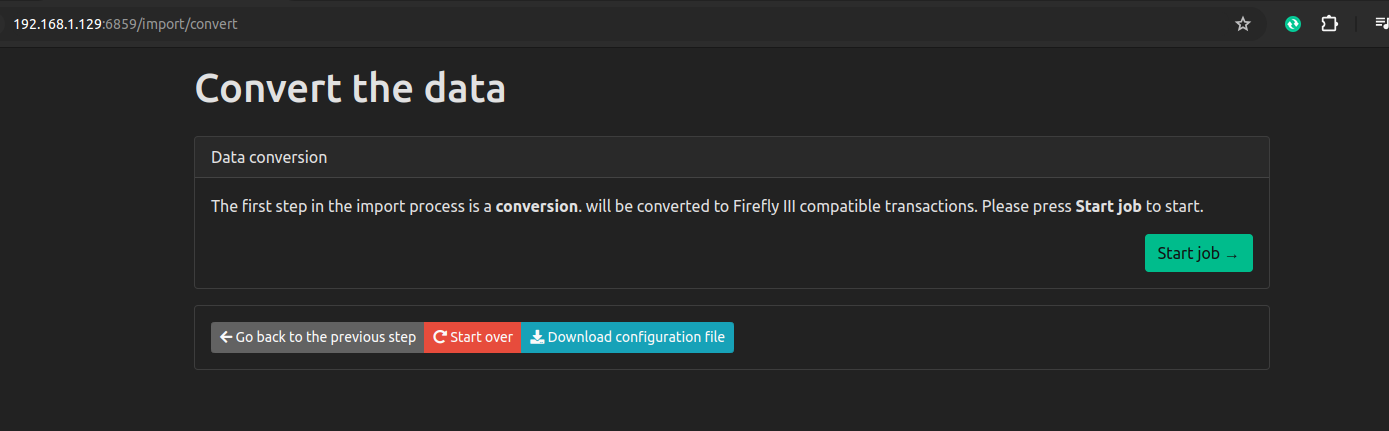
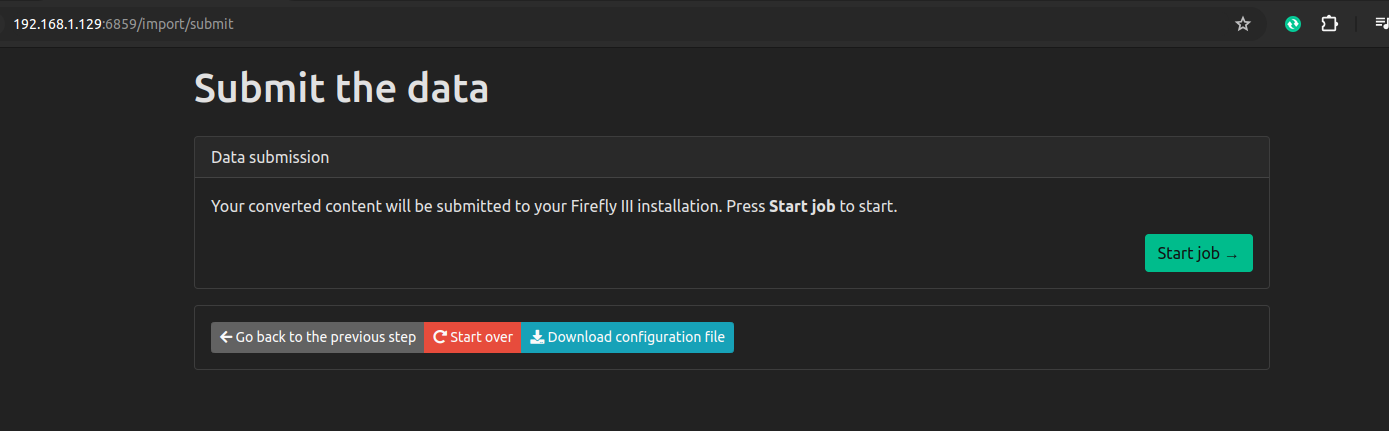
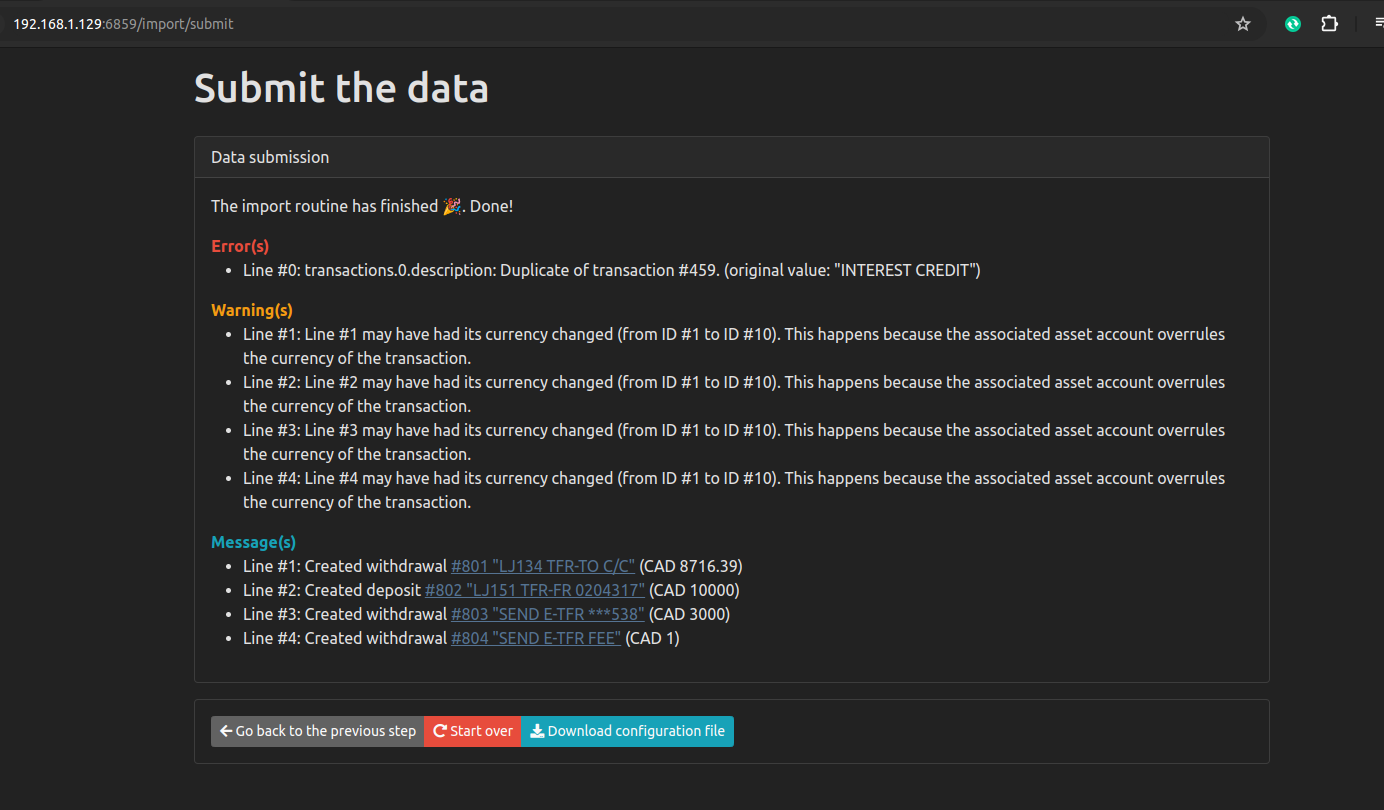
There seems to be no way to save all these import choices so I’ll need to remember these steps each month I guess. Hopefully, I don’t make any mistakes.
The initial import worked alright, and even subsequent imports a few weeks later were fine. Overlapping transactions in the CSV files didn’t result in duplicate entries in Firefly. So the base functiionality is there, but the main annoyance is the need to repeat a whole set of configurations on every single import. It would be very user-friendly, if an account’s import settings were remembered. For example, why do I need to enter the Firefly URI, an unchanging clientid, an unchanging date format, etc every single time. I can see this being a pain I will want to do at most once a month.
WebUI
After creating the accounts with a starting balance, importing transactions, then deleting and retrying a few times… I was able to get our chequing, saving, and credit cards (Visa & Mastercard) into Firefly.
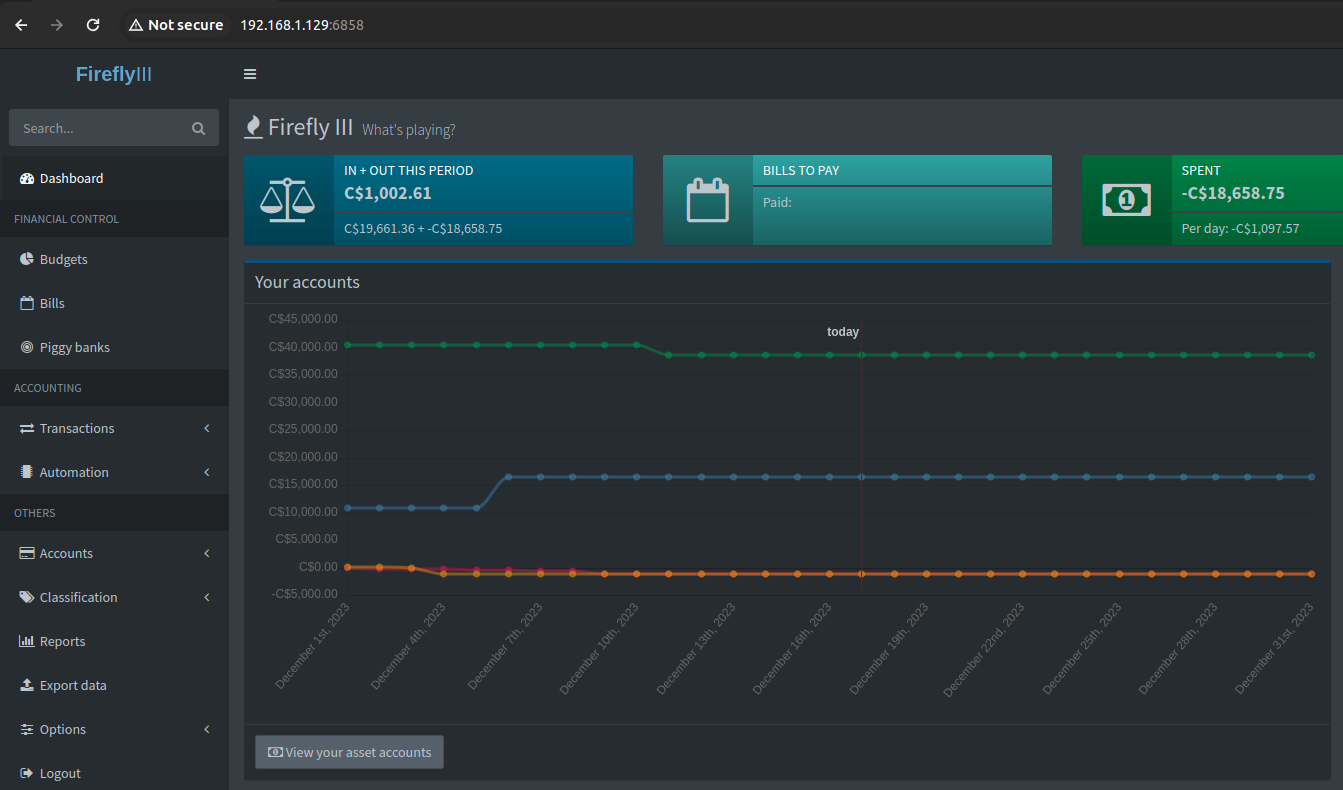
Conclusion
While I have a monthly manual import working now, I have zero categorization of the incoming transactions yet. So, I’m not able to answer the only questions I am interested in:
- How much did I spend last month total?
- How much did I spend, by category, last month?
Still lots of work to go, but as manual replacement for Mint, I think Firefly-III is promising.
]]>