![]()
While the publicly available LLMs such as OpenAI’s ChatGPT, Anthropic’s Claude, Google’s Gemini, and X.ai’s Grok are all very useful, they have two primary drawbacks:
- They all offer a free tier with limits on usage amount and types, but then start charging users for premium tiers.
- By definition, when you chat with these public LLMs, you are sending your data (your text) to that company, violating your privacy.
Meta (who owns Facebook) decided to take a different route and release their LLM as free to use on one’s own computer. While not open-source, Meta offers Llama models downloads as free for us to test ourselves. Most amazingly, once downloaded the software model does not require further Internet access to use, allowing for actual private conversations. With people starting to use LLMs as fill-ins for their psychologist/psychiatrist, they then no longer need to share their private thoughts with a large corporation.
Ollama with a GPU
The easiest way I found to run LLM models using Ollama was with Open-WebUI, running on Docker. My first test machine was a gaming PC with an AMD Ryzen 7 5700x 8-core CPU paired with a Nvidia 3070ti GPU. This is decidely mid-range personal hardware, now a few years old. It is not a super powerful system by any means.
From a Powershell on this Windows 11 system, I loaded the image and ran the following
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
This pulls the Open-WebUI image, with Ollama bundled within, and enables support for my Nvidia GPU.
Then I browsed to http://localhost:3000 to create my first user and start interacting with Open-WebUI. First job was to pull down the newish Llama 3.2 model which was small enough to run on my older computer. Took a little while to work this out:
- Click your profile icon in the top-right corner.
- Choose ‘Settings’ from the drop-down menu.
- In the Settings dialog, choose ‘Admin Settings’ along the left.
- In Admin Settings, choose ‘Connections’, and select the wrench icon to ‘Manage Ollama API Connections’
- In that dialog, starting typing ‘llama’ in the box ‘Pull a model from Ollama.com’
- Find the model you want, and click the Download icon.
Alright, once you have loaded a model, you can then start chatting with it. For example:
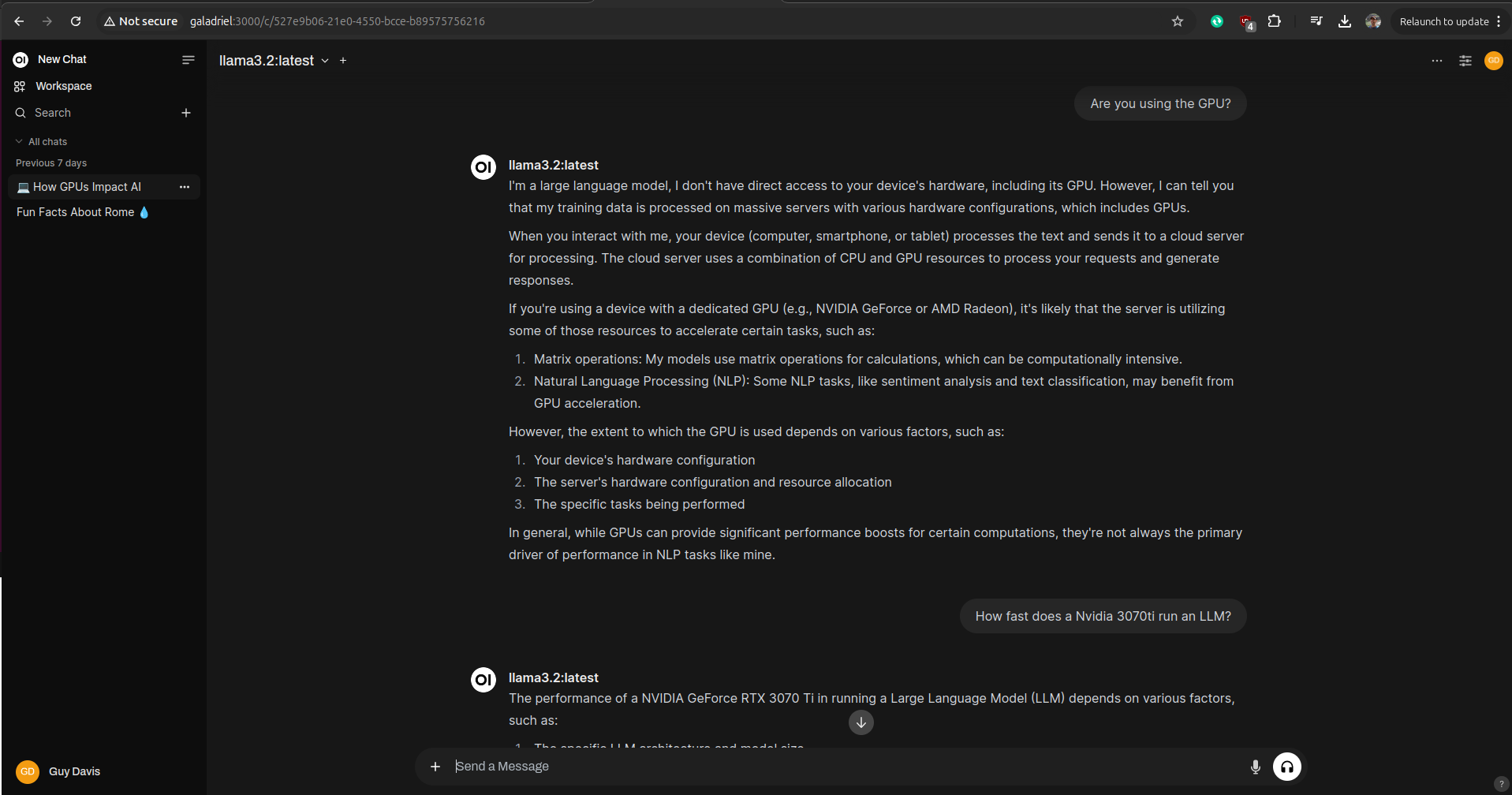
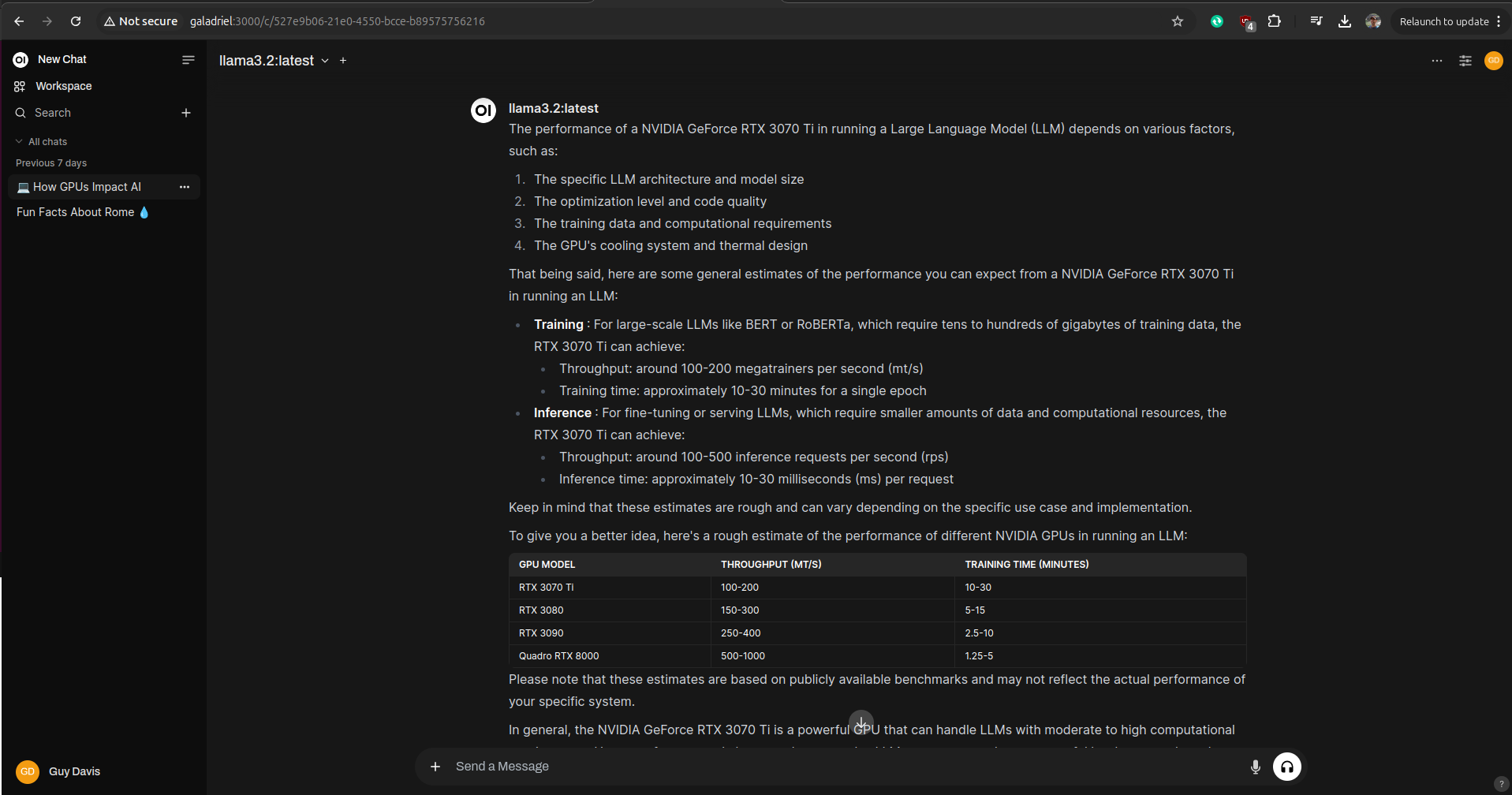
I was watching GPU load in the Performance tab of the Window’s Task Manager and each response from the model did show GPU usage. As well, each response has a small ‘info’ icon below it so you can see the time it took to construct. I was seeing responses in a few seconds. Then I asked if my GPU was any good:
Offline Mode
I then disabled my computer’s network connection and asked the model to tell me about the history of Rome. Even with no Internet access, the model gave a useful response, showing just host much info is embedded within the multi-GB sized model download.

Ollama with only a CPU
You don’t actually need a GPU to run Ollama, but it certainly results in a more responsive chatting experience. My other test system was a similar gaming PC with the same CPU, but an AMD Radeon 6750xt GPU. Unfortunately, in the world of machine-learning and artificial-intelligence, support from AMD for consumer-level GPU support is neglible compared to Nvidia. In this case, that Radeon GPU is useless and Ollama relied exclusively upon the CPU to give responses.

The ‘Info’ pop-up for the response above showed about 20 seconds, coming in about 10x slower than a similar response on the machine with an Nvidia GPU. So clearly, an Nivida GPU is still highly recommended for using these LLMs on one’s own computer.
Conclusions
Overall, it’s great that these “open-weight” models exist and can be run on consumer hardware. I don’t want only large corporations to control this technology. However, given that the actual training of these models takes data-center levels of hardware (millions of $$$), it seems that only large corporations may end up controlling the final destination of these LLMs. Definitely a space to watch…
More in this series…
- Google Gemini - Google Gemini
- Anthropic Claude - Anthropic Claude
- Llama 3 - Llama 3
- ChatGPT 4o - ChatGPT 4o
- Anthropic Claude in Canada - Claude eh?
- LLMs on Android - AI in your pocket
- Google Imagen3 - AI Image Generation
- Azure AI Studio - AI on MS Azure
- Google AI Studio - AI on Google
- Deepseek - Trying small distills locally.
- Google Gemma - Google Gemma v3 released.