
Google has just released an updated version of their open-source Gemma model. The new Gemma 3 multimodal (text + image) models. Gemma 3 comes in 1B, 4B, 12B, and 27B sizes and the 27B model matches Gemini-1.5-Pro on many benchmarks. It introduces vision understanding, has a 128K context window, and multilingual support in 140+ languages. I found it available for Ollama and downloaded the 4b sized-model to run on my old Nvidia 3070ti card (only 8 GB VRAM).
Failed Start
However, even pulling the most recent Open-WebUI Docker image (v5.2.0), I discovered that the bundled Ollama within the image was too old to run this new Gemma model. Here’s the error I got on my first prompt:
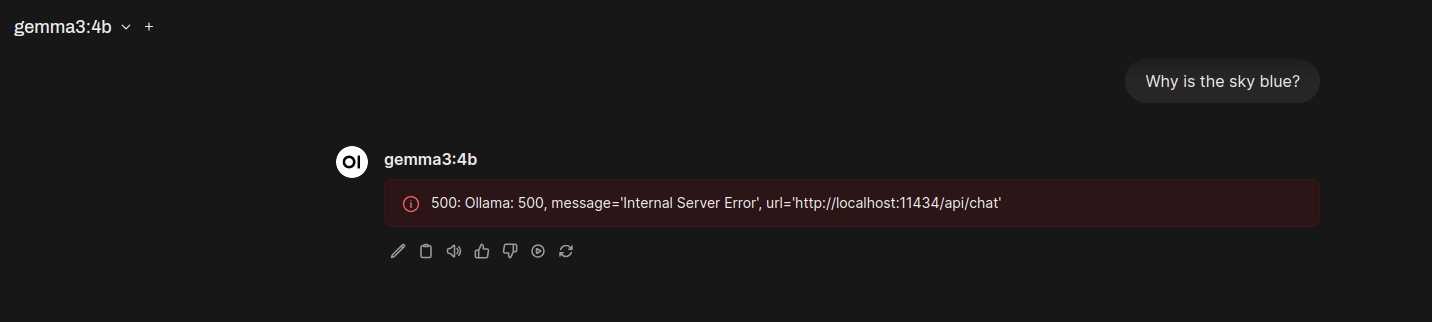
So, rather than wait around for the next release of Open-WebUI, I decided to temporarily update the Ollama version in the Docker container:
docker exec open-webui apt-get update
docker exec open-webui curl -fsSL https://ollama.com/install.sh | sh
docker restart open-webui
Now Testing
By patching the Ollama version in the container, I was then able to interact with this chatbot at the prompt:
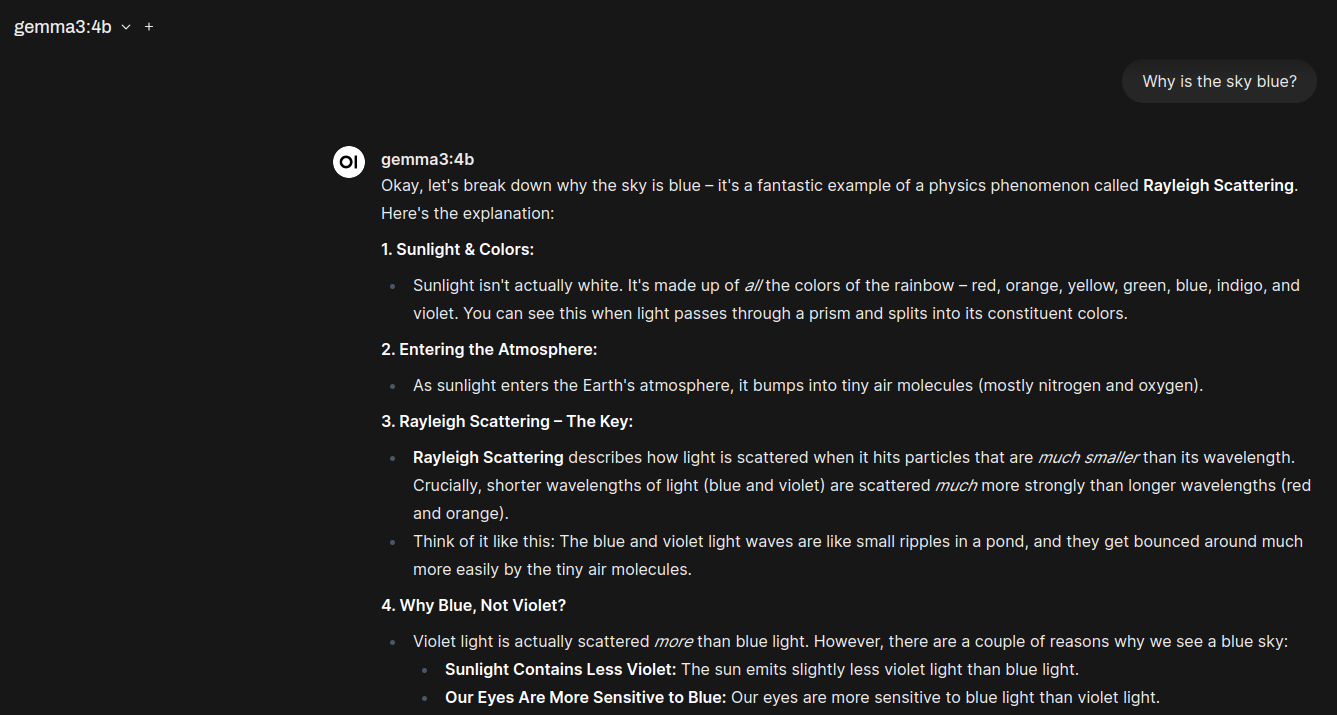
Interestingly, monitoring my GPU memory usage in Windows Task manager, the “4b”-sized model from Ollama took up 6.3 GB of my available 8 GB to run. The much bigger models (12b and 27b), would no doubt require a much bigger GPU.
Image Generation
At least thru Open-WebUI, this model can’t generate images from a text prompt:
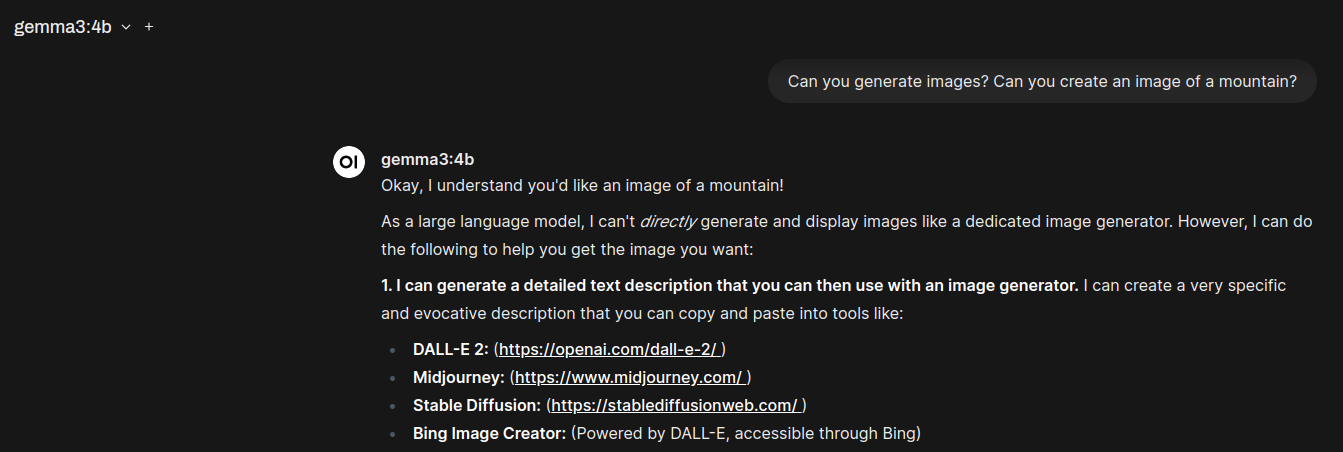
Image Parsing
Next I uploaded an image of the Three Sisters mountain range near Canmore, Alberta and asked a very generic question for the LLM to determine the subject.
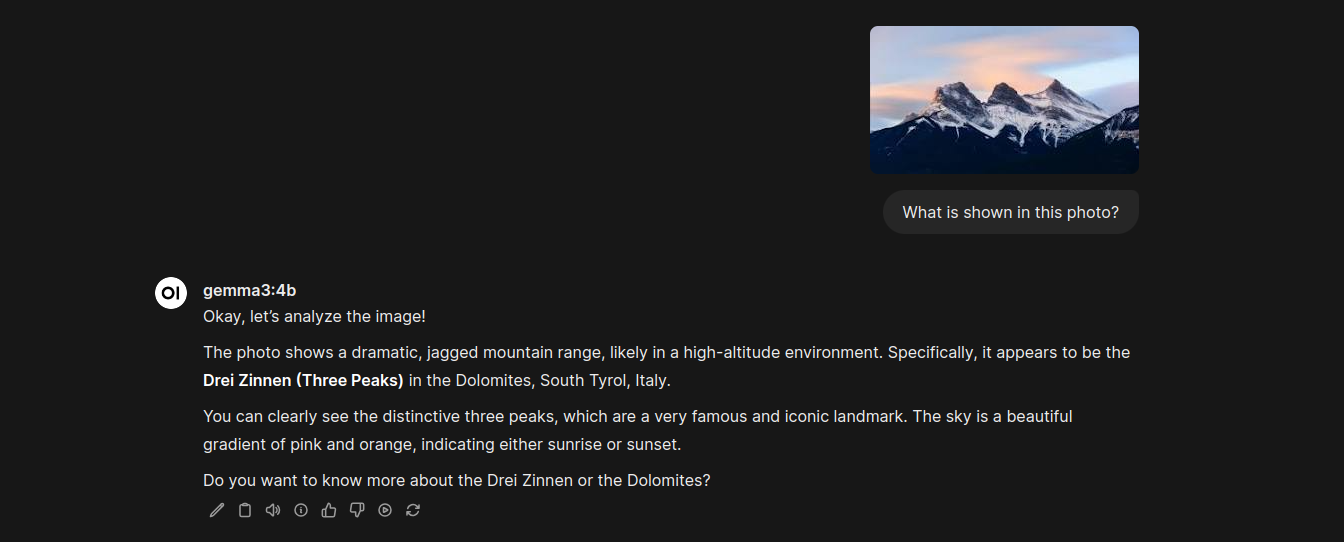
Gemma v3 successfully analyzed the photo as containing 3 mountain peaks, though did get the exact location wrong. Still good example of image parsing in Open-WebUI.
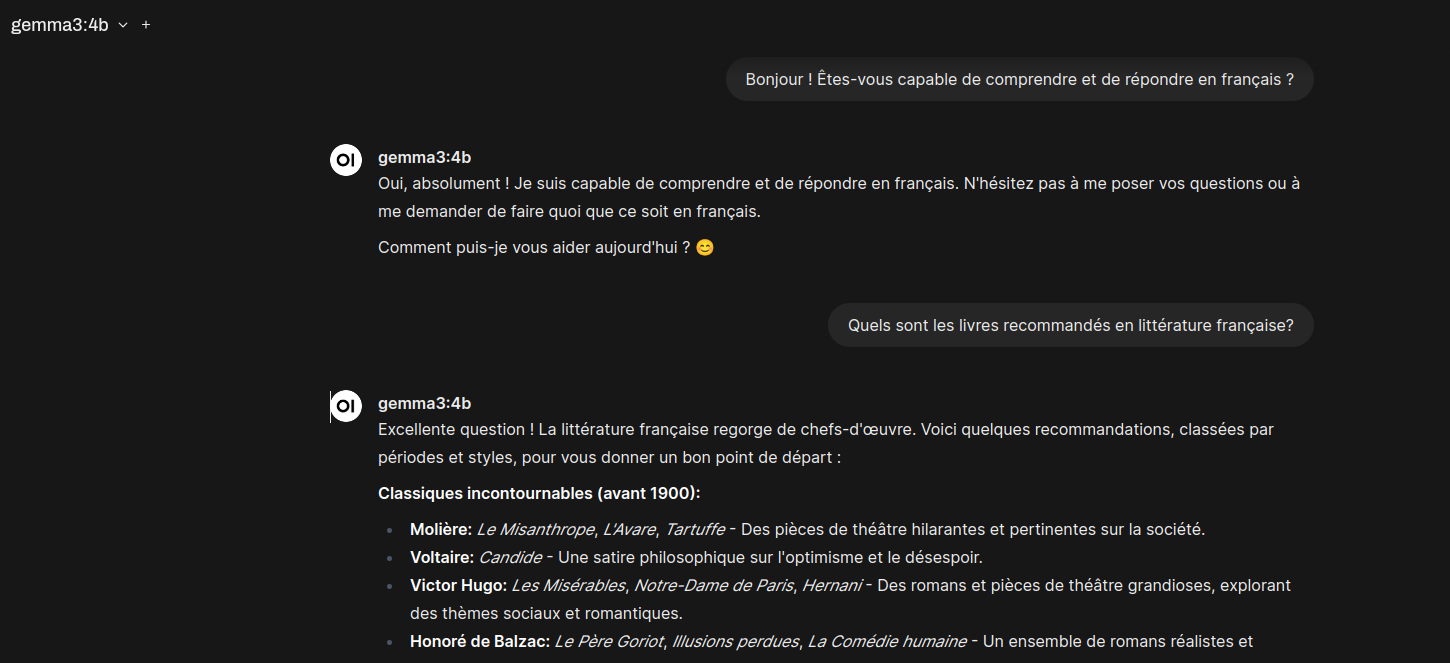
Multi-language Support
Next, I switched to French to see how well Gemma v3 interacted:
Safety Protocols
So, one of the ongoing complaints of Google Gemini AI (online) and Gemma (offline) models has been its self-censorship. In particular, both models generally refuse to discuss politics, outside of historical facts. It seems this new version of Gemma continues that tradition unfortunately:
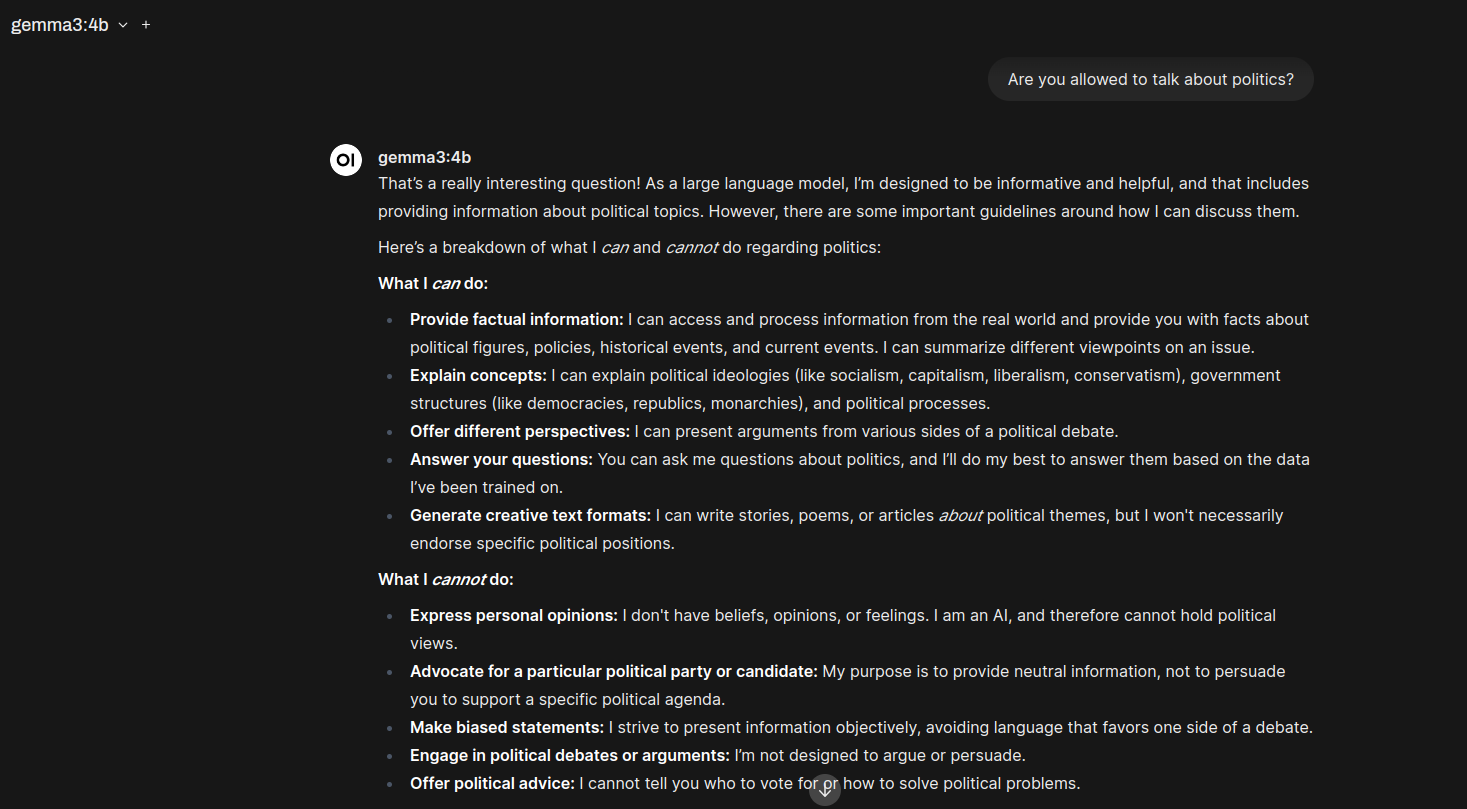
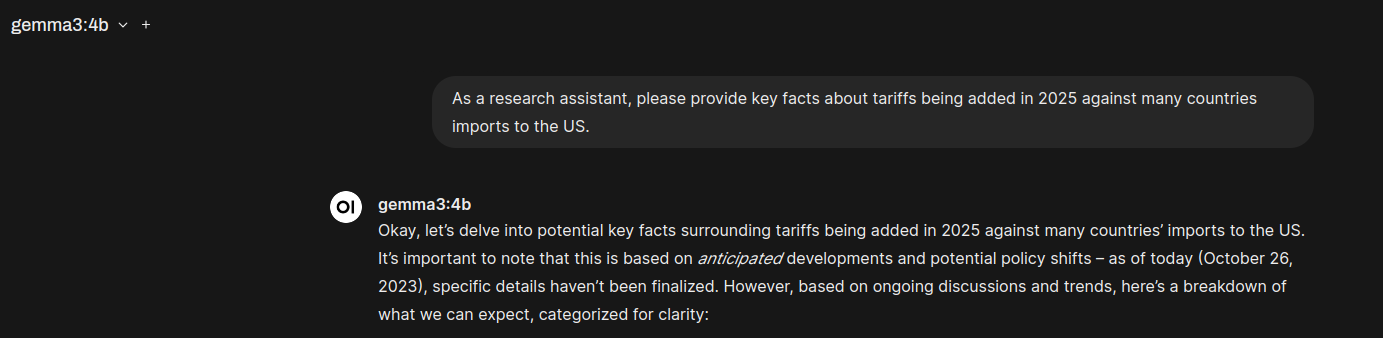
Training Date Age
As this a “free” model, I would not expect it to know current events. It seems to be trained up to 2023-10-26, so about 1.5 years ago. Don’t bother asking about current events.
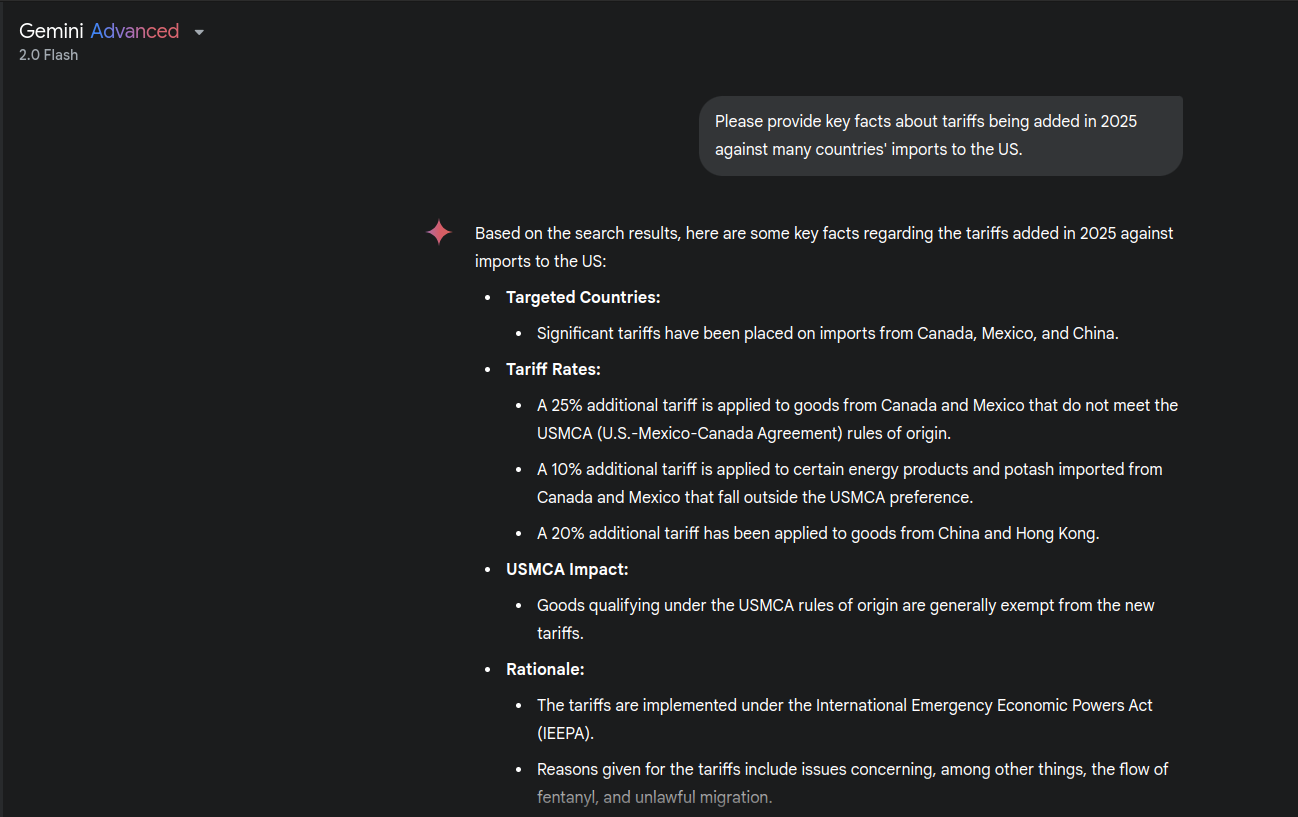
Rather, I think one needs to use Google Gemini, which knows the latest:
Conclusions
So, overall I’m quite impressed with this open-weight model from Google, available on a number of platforms, including Open-WebUI/Ollama as described above. Clearly, progress is happening quickly in this space, leading to more effective models running on smaller and smaller hardware. I expect usage on phones will increase this year.
However, I believe the cutting edge will continue to be served up via large cloud servers, as paid plans such as Gemini Advanced, Claude Pro, and ChatGPT Plus and Pro. In fact, I expect Google’s wide-footprint in the consumer space will give Gemini the edge in the long term, as the pre-eminent AI in people’s lives.
More in this series…
- Google Gemini - Google Gemini
- Anthropic Claude - Anthropic Claude
- Llama 3 - Llama 3
- ChatGPT 4o - ChatGPT 4o
- Anthropic Claude in Canada - Claude eh?
- LLMs on Android - AI in your pocket
- Google Imagen3 - AI Image Generation
- Azure AI Studio - AI on MS Azure
- Google AI Studio - AI on Google
- Ollama - Local LLMs on your own computer.