![]()
With all the hype about LLMs, the stock market was surprised by the Deepseek r1 model release in late January, leading to a large selloff in Nvidia shares. The thinking was that Deepseek trained their model very cheaply, barely using Nvidia chips, for $5 million, instead of the billions being spent by large US firms. A week later, it turns out the news headline was wrong and they spent $1.6 billion using 50k Nvidia GPUs. Good example of why the headline news should be read with skepticism.
As I have been playing around with small models on an old gaming PC using Ollama, however with only a RTX 3070ti GPU having 8 GB VRAM, running the fullsized Deepseek r1 is not possible. This is too bad as apparently the r1 model is quite good. Instead, it is possible to try running a distilled model. These are actually Qwen models that have been distilled using Deepseek r1.
In my case, I’ll try the 7b model, downloading via “Settings > Admin Settings > Connections > Manage Ollama API Connections”:
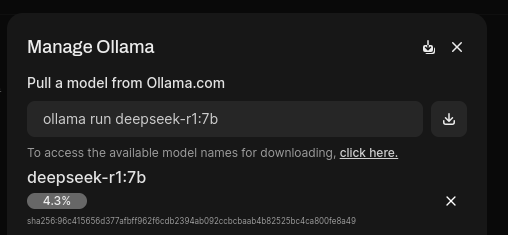
This results in the chat window shown:
As r1 is a “thinking” model it is quite verbose, but does a good job of explaining its though process in the <think> tag:
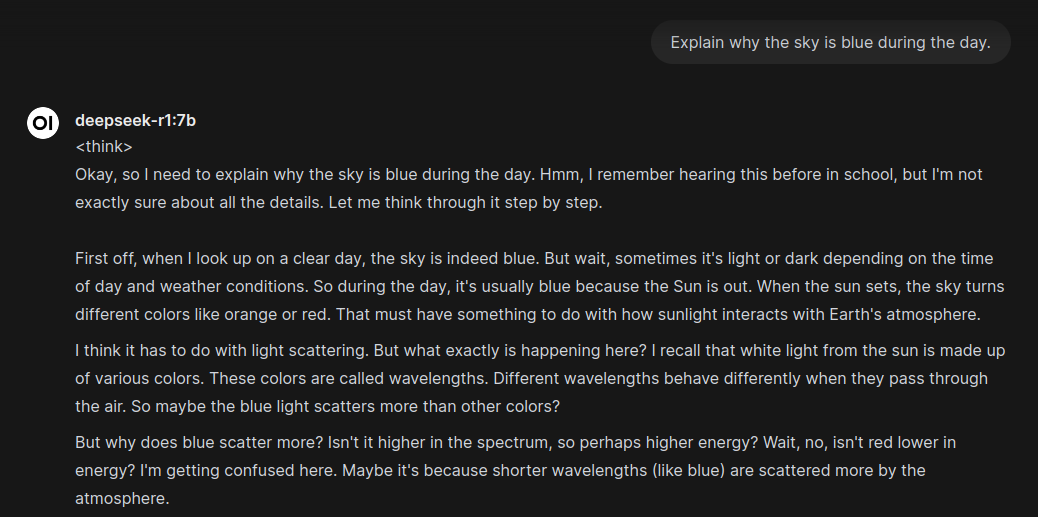
This response came back in roughly 20 seconds, which wasn’t too bad for my old GPU. I followed up with: “Is that on planet Earth only? What about on Mars?”
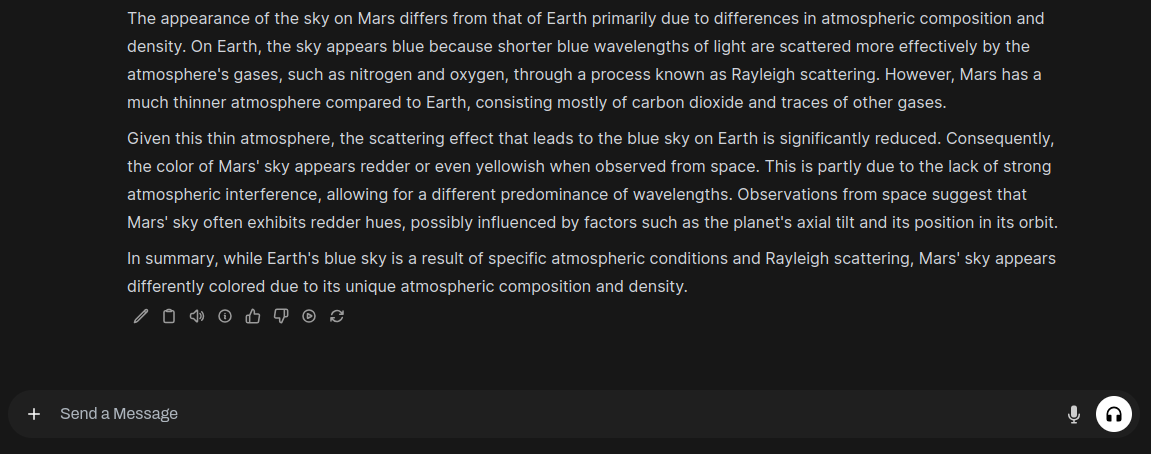
Conclusions
This dabbling with a distilled model on old hardware is fun, but not at all reflective of Deepseek’s true performance. Hugging Face reports this model “achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks.” Overall, the LLM space continues with rapid improvements. Just this week Google released Gemini 2.0 which looks promising.
More in this series…
- Google Gemini - Google Gemini
- Anthropic Claude - Anthropic Claude
- Llama 3 - Llama 3
- ChatGPT 4o - ChatGPT 4o
- Anthropic Claude in Canada - Claude eh?
- LLMs on Android - AI in your pocket
- Google Imagen3 - AI Image Generation
- Azure AI Studio - AI on MS Azure
- Google AI Studio - AI on Google
- Ollama - Local LLMs on your own computer.
- Google Gemma - Google Gemma v3 released.