Each time I come back to Kubeflow, I perform a fresh install to get the latest. Often, I find the default install path errors out, so I go looking for a workaround. Here’s the latest as of early December 2020 for Ubuntu 20.04 running on a local server:
sudo snap install microk8s --classic --channel=latest/edge
export KUBEFLOW_HOSTNAME="http://<LOCAL_SERVER_IP_ADDR>:8081"
KUBEFLOW_DEBUG=true microk8s enable kubeflow
microk8s juju config dex-auth static-password=<NEW_PASSWORD>
microk8s.kubectl port-forward -n kubeflow service/istio-ingressgateway 8081:80 --address 0.0.0.0
While the Kubeflow dashboard forwarding is now working this month, unfortunately a new bug means you need to set a new password after enabling kubeflow before logging in as shown:

To get to the dashboard:

Development Setup
Using the sample Kubeflow pipelines, I set up a local development environment on an old Windows 10 laptop. First, I installed Anaconda, then setup an isolated Python env within a Gitbash shell in VS Code, after enabling Gitbash to read .bash_profile:
conda init bash
conda create --name mlpipeline python=3.7
conda activate mlpipeline
pip3 install kfp --upgrade
Compiling a ML Pipeline
Executed the following to complile the [sample Kubeflow pipeline]:
git clone git@github.com:kubeflow/pipelines.git
cd pipelines
export DIR=./samples/core/sequential
dsl-compile --py ${DIR}/sequential.py --output ${DIR}/sequential.tar.gz
The compiled pipeline is then ready for upload to the Kubeflow cluster: ./samples/core/sequential/sequential.tar.gz
Deploying the Pipeline
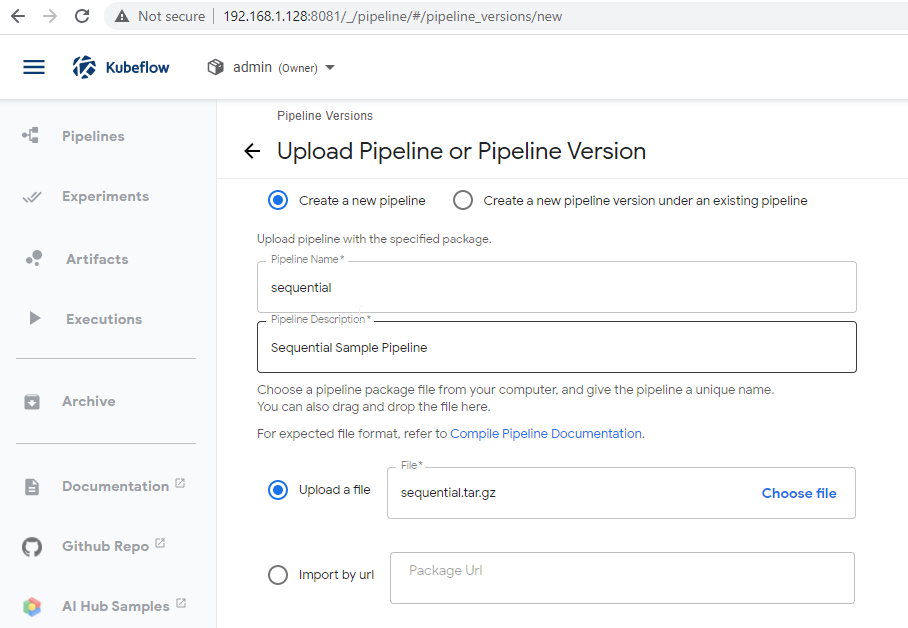
After upload, the pipeline is shown both as a Graph and YAML:

Running the Pipeline
Clicking Create Run button allows for execution of the pipeline on the Kubeflow cluster.

Output is shown soon after for a sample pipeline such as this:

While this upload process worked alright, I did prefer the Jupyter notebook interactive approach for quickly trying out new ML code.
Conclusions
While I’ve had some trouble getting a consistent working on-prem install of Kubeflow, once up and running it does seem to be worthwhile platform for ML deployments. Beyond my lab experiments however, I’d probably recommend running it on a managed Kubernetes cluster such as GKE, AKS, or EKS in production.
More in this series…
- microk8s on ubuntu - Single instance cluster
- microk8s upgraded - Upgrading to k8s 1.19
- kubeflow setup - Enabling ML workflows
- MNIST notebook - Using Jupyter notebooks on Kubeflow