This covers my work on the second lesson of the Fast AI course. The lesson looked at both data prep/cleaning and then started into SGD.
Data Prep and Cleaning
Drawing on my old days working with data quality software, this lesson emphasized the importance of good data sets, in particular good training sets. Often a good scripting language, such as Python, is ideal for the wrangling required to get data ready for your project.
In this example, fast.ai library provides verification:
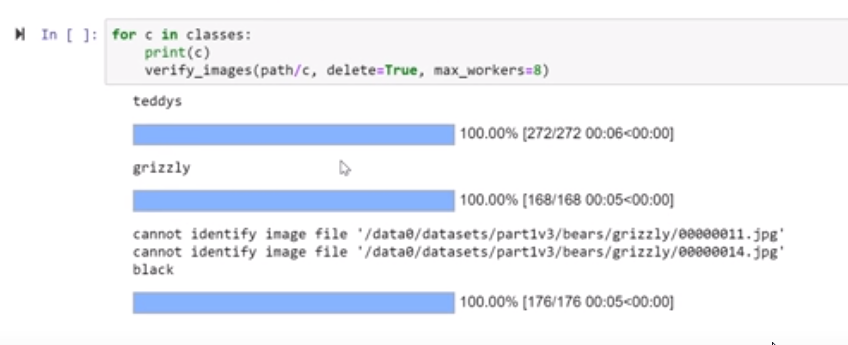
and, in this case, visual validation:
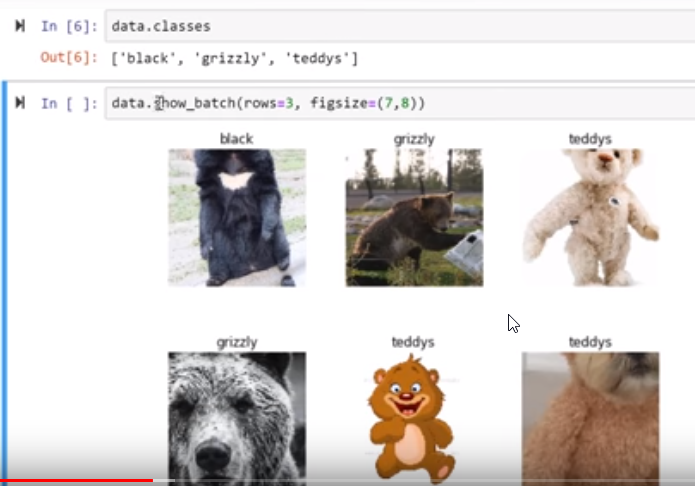
Stochastic Gradient Descent
Next up, the instructor covered the basic data structures we’d be using: namely tensors which just multi-dimensional matrices. Using regression, we then attempted to find functions that could predict a simple set of data while minimizing the mean-squared error.
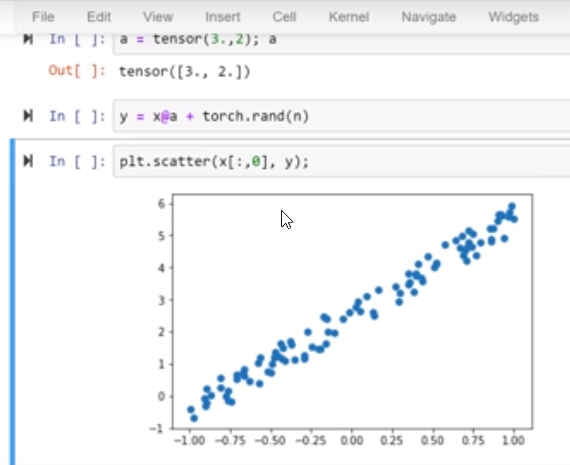
The beauty of stochastic gradient descent is its iterative approach to optimizing a function to match the data. In particular, SGD uses a randomly (stochastic) selected search path, but measures each step along the way for decreasing error.
Takeaways
In this lesson, we then extended from the simple function example, to a classifying function for teddy bears, using mini-batches to ensure a performant search. At the end, we had a decent machine learning algorithm (aka a function) that could pretty reasonably identify teddy bears in an image.