A while back, I discovered the predictive analytics tool, RapidMiner and wanted to try it out. Given my recently loaded US baby names data set, I thought I’d ask some silly questions… more to see how Rapid Miner models work, than to accurately predict anything.
Decision Tree
I wondered if one could predict a US person’s most likely birth state given their first name, their gender, and their year of birth. First off, I created a Rapid Miner process which:
- Creates a 1000 record training set:
SELECT "name", "state", "gender","count", "year" FROM "public"."statenames" ORDER BY RANDOM() LIMIT 1000 - Loads a test set of 20 records:
SELECT "name", "gender", "year", "state" as "actual_state" FROM "public"."statenames" ORDER BY RANDOM() LIMIT 20 - Set attribute roles as needed to binomial (gender) etc.
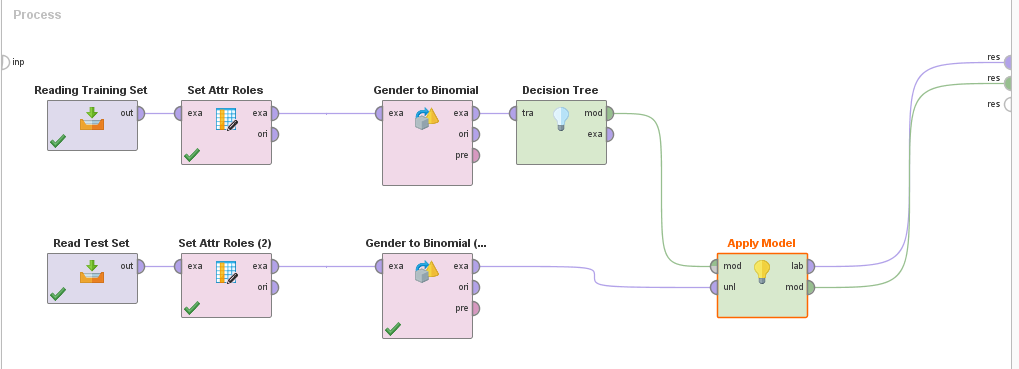
- Then trained a decision tree model on the training data set. Interestingly, the decision tree ignored name and started to split solely on birth year, occasionally considering gender, in order to predict birth state.
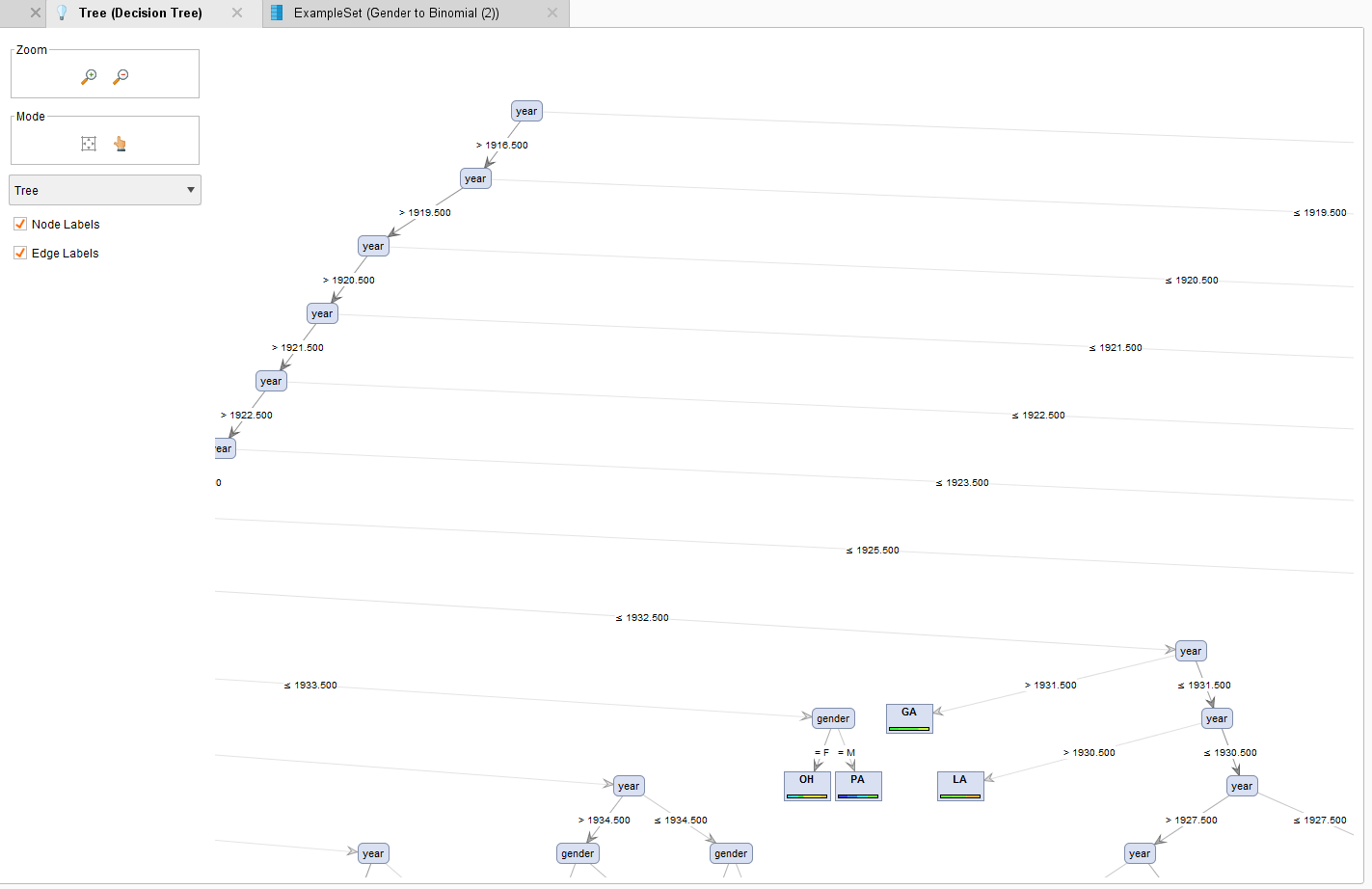
- Applied the model to the test data set to predict a name/gender/year record’s birth state. As you can probably guess, a decision tree model based solely on year and gender does a horrible job of predicting birth state. See the two green columns in the results below (actual vs predicted).
So this use of decision tree was clearly a mis-applicaton for this data set and question.
Naive Bayes
So let’s narrow the solution space by seeing if we can predict gender, a binomial, based on name and birth year using the national names data set. As an aside, there are a number of names which have both male and female records for a given year. For example, my own name ‘Guy’ has a handful of female counts for 59 different years. I leave it to the read to decide if these are accurate records (actual baby girls named ‘Guy’) or simply a data quality problem.
select year, count from nationalnames where name = 'Guy' and gender = 'F' order by year desc
So, I created a RapidMiner process with Naive Bayes model, increased the training set size to 10,000 records, and added a Performance (Binomial Classification) operator as shown:
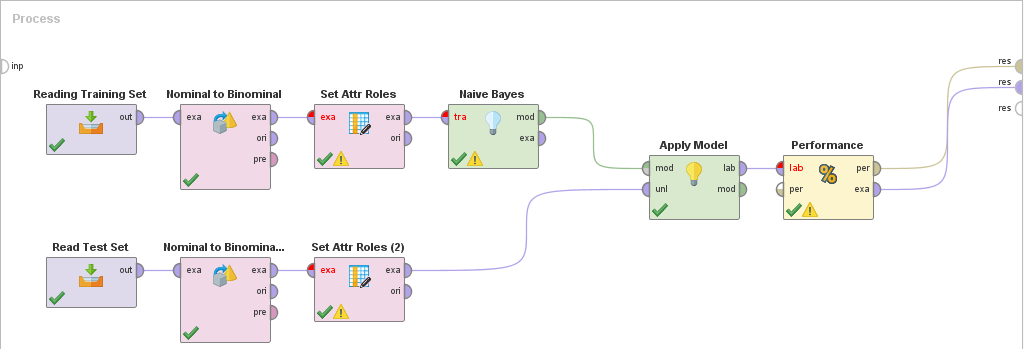
Repeated runs generated results approximating a coin flip, so not great. Here’s an example:
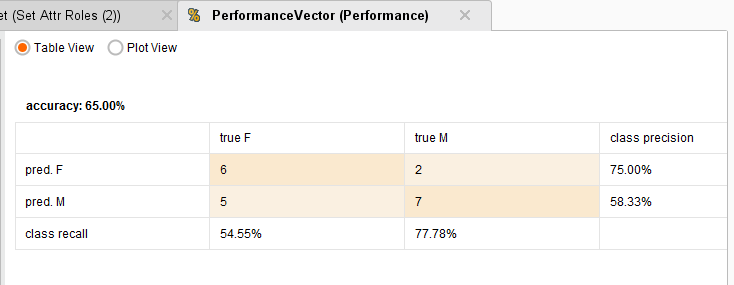
Better Results
While the results above are not particularly predictive, I did learn a good deal about Rapid Miner and its algorithms. For rapid prototyping, it is a very effective tool. For a better result from the name data, check out this example which predicts age from name and gender.