Having just signed up at Kaggle to explore machine learning tutorials with some neat data sets, I came across a familiar dump of US baby names over the years. The tutorial below covers how to load the dataset into PostgreSQL to allow for various data analysis approaches.
Nearly a decade ago, I built a Google maps mashup of baby names scraped from sources around the world to visualize name usage geographically. The map helped my wife and I choose the names of our two boys: Gavin and Connor. With my recent interest in machine learning, I thought it would be fun to explore ML algorithms on the babynames data set.
To get started, let’s create a Postgres database and two tables. You’ll need the PostgreSQL database for this.
create database names;
\connect names;
create table nationalnames (id integer primary key, name varchar(255), year smallint, gender char(1), country char(2), count integer);
copy nationalnames(id,name,year,gender,count) from '/path/to/data/NationalNames.csv' DELIMITER ',' CSV HEADER;
update nationalnames set country = 'US';
create table statenames (id integer primary key, name varchar(255), year smallint, gender char(1), country char(2), state char(2), count integer);
copy statenames(id,name,year,gender,state,count) from '/path/to/data/StateNames.csv' DELIMITER ',' CSV HEADER;
update statenames set country = 'US';
This gives us 1.8 million US-wide name records dating back to 1880 and 5.6 million state-wide name records dating back to 1910. To then plot from the data to begin exploring it, try the following in Python (with SQLAlchemy, Pandas, and Matlab). For example, the popularity of my name over time:
import pandas as pd
import matplotlib.pyplot as plt
from sqlalchemy import create_engine
engine = create_engine('postgresql://postgres@localhost:5432/names')
df = pd.read_sql_query('select year, count from nationalnames where name = \'Guy\' and gender = \'M\'', con=engine)
plt.plot(df['year'], df['count'])
plt.show()
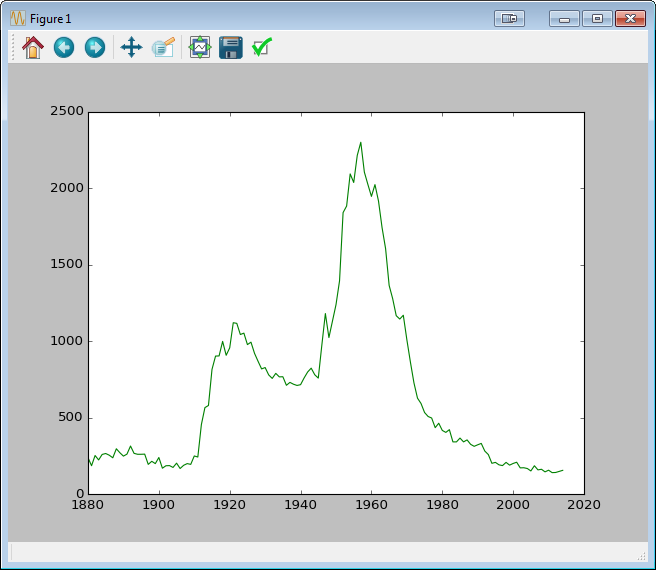
Interesting that my name’s popularity peaked in the 1957 at over 2300 babies. By the time I was born in 1976 though, only about 500 babies shared that name in the US, with the popularity falling precipitously.
Up next, we’ll use this dataset for more interesting analysis and prediction.