Unlike ETL, data virtualization allows one to repurpose their data while leaving it in the original source. Since there is no staging or warehousing, the data is always live and up to date.
The main downside of data virtualization of disparate data sources is slower performance. If, on each query at your virtualization layer, the request must go all the way back to the underlying data source, then query times will likely go up compared to cached solutions.
In the Postgres world, data virtualization is accomplished with Foreign Data Wrappers (aka FDW). These connectors provide data access to various other data stores such as Oracle, SQL Server, MySQL, Mongo, flat files, etc. The beauty of FDW is that your PostgreSQL database becomes the common data interface for all clients.
Postgres FDW + Multicorn
To make use of Postgres’ Foreign Data Wrappers, I used the following successfully. If interested, failed alternatives are listed at the end of this post.
- CentOS 7.
- PostgreSQL 9.5.
- Multicorn 1.3.2 on Python 2.7
- sqlalchemy 1.0.14
Once I had a CentOS 7 VM running inside Vagrant, the next step was to install Postgres 9.5 following the directions here and here.
With PostgreSQL was installed, I was able to start adding the rest of the dependencies:
yum install -y python-devel multicorn95 epel-release vim python-pip python-sqlalchemy
Then, at the Postgres prompt, enable the Multicorn extension:
CREATE EXTENSION multicorn;
Next up is to start exposing data in Postgres, virtualized from other backend data stores like MySQL, Oracle, and MS SQL Server.
Exposing MySQL Data
For this example, I’ll be exposing sample data from MySQL as a table within our PostgreSQL database. Here’s the data, queried in MySQL Bench:
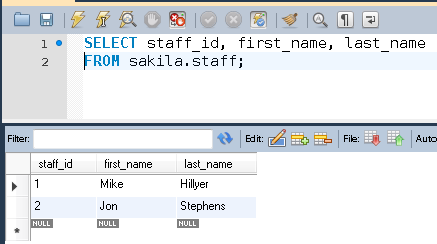
You’ll need the MySQL driver for Python to allow SQLAlchemy to connect:
yum install -y MySQL-python
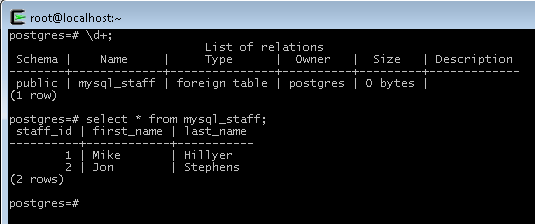
Then to create the foreign table to MySQL:
CREATE SERVER MYSQL_SAKILA foreign data wrapper multicorn options (
wrapper 'multicorn.sqlalchemyfdw.SqlAlchemyFdw'
);
create foreign table mysql_staff (
staff_id integer,
first_name varchar,
last_name varchar
) server MYSQL_SAKILA options (
tablename 'staff',
db_url 'mysql://sakila:sakila@HOST_NAME/sakila'
);
Exposing Oracle Data
For this example, I’ll be exposing sample data from Oracle as a table within the PostgreSQL database. Here’s the data, queried in Oracle SQL Developer:
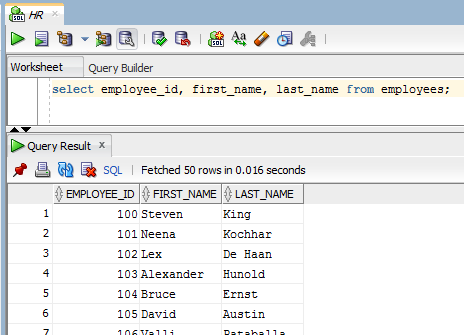
First, we need to install the Oracle libraries needed to build the cx_Oracle driver for SQLAlchemy. Once you’ve downloaded the basic and devel Oracle RPMs, install them:
rpm -ivh /vagrant/oracle-instantclient11.2-basic-11.2.0.4.0-1.x86_64.rpm
rpm -ivh /vagrant/oracle-instantclient11.2-devel-11.2.0.4.0-1.x86_64.rpm
Then set some Oracle environment variables before installing cx_Oracle. Add the following lines to /etc/profile:
# Required for Oracle database connections
export ORACLE_VERSION="11.2"
export ORACLE_HOME="/usr/lib/oracle/$ORACLE_VERSION/client64"
grep -q "$ORACLE_HOME" <<< ":$PATH:" || export PATH=$PATH:"$ORACLE_HOME/bin"
if [ -z $LD_LIBRARY_PATH ]; then
export LD_LIBRARY_PATH="$ORACLE_HOME/lib"
else
grep -q "$ORACLE_HOME" <<< ":$LD_LIBRARY_PATH:" || export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:"$ORACLE_HOME/lib"
fi
Then create a new file named /etc/ld.so.conf.d/oracle_instantclient.conf with only this line: /usr/lib/oracle/11.2/client64/lib and run following as root in shell:
ldconfig
systemctl stop postgresql-9.5.service
systemctl start postgresql-9.5.service
yum groups mark convert "Development Tools"
yum groupinstall "Development Tools"
pip install cx_Oracle
At this point you should be able to query your Oracle database from Python directly. Here’s an example script, just change host name, port, and service name as needed:
import sqlalchemy
engine = sqlalchemy.create_engine("oracle+cx_oracle://hr:hr@(DESCRIPTION = (LOAD_BALANCE=on) (FAILOVER=ON) (ADDRESS = (PROTOCOL = TCP)(HOST = HOST_NAME)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = XE)))")
result = engine.execute("select * from employees")
for row in result:
print row
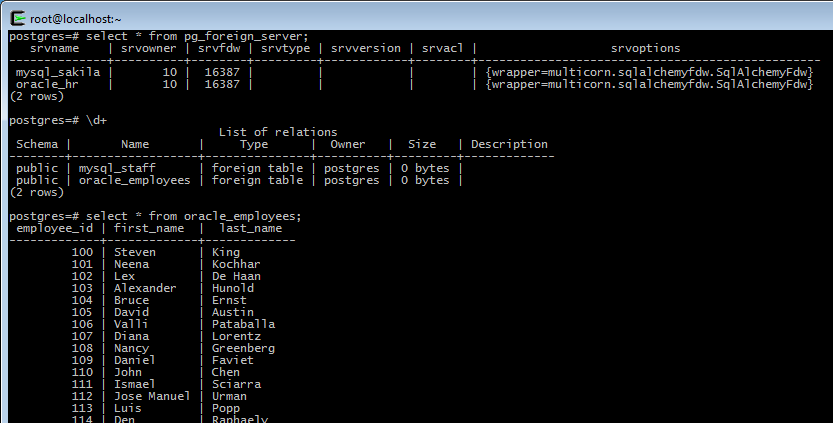
Assuming a successful query result above, then it’s time to create the foreign table in PostgreSQL:
CREATE SERVER ORACLE_HR foreign data wrapper multicorn options (
wrapper 'multicorn.sqlalchemyfdw.SqlAlchemyFdw'
);
create foreign table oracle_employees (
employee_id integer,
first_name varchar,
last_name varchar
) server ORACLE_HR options (
tablename 'employees',
db_url 'oracle+cx_oracle://hr:hr@(DESCRIPTION = (LOAD_BALANCE=on) (FAILOVER=ON) (ADDRESS = (PROTOCOL = TCP)(HOST = HOST_NAME)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = XE)))'
);
Exposing SQL Server Data
For this example, I’ll be exposing sample data from SQL Server as a table within the PostgreSQL database. Here’s the data, queried in MS SQL Server Management Studio:
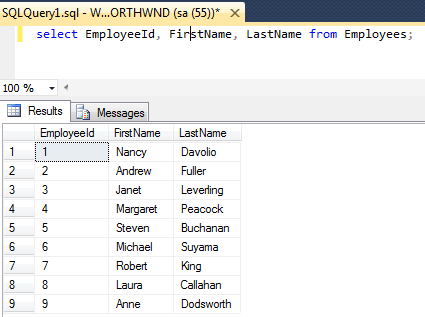
First, I needed the pymssql driver for Python:
yum install -y freetds
pip install pymssql
At this point you should be able to query your SQL Server database from Python directly. Here’s an example script, just change host name as needed:
import sqlalchemy
database_type = "mssql+pymssql"
user_name = "northwnd"
user_pass = "northwnd"
database_uri = "HOST_NAME"
connection_string = r"{0}://{1}:{2}@{3}/NORTHWND".format(
database_type,
user_name,
user_pass,
database_uri,)
print(connection_string)
engine = sqlalchemy.create_engine(connection_string, echo=True)
result = engine.execute("select EmployeeId, FirstName, LastName from Employees")
for row in result:
print row
Assuming a successful query result above, then it’s time to create the foreign table in PostgreSQL:
CREATE SERVER MSSQL_NORTHWND foreign data wrapper multicorn options (
wrapper 'multicorn.sqlalchemyfdw.SqlAlchemyFdw'
);
create foreign table mssql_employees (
EmployeeId integer,
FirstName varchar,
LastName varchar
) server MSSQL_NORTHWND options (
tablename 'Employees',
db_url 'mssql+pymssql://northwnd:northwnd@HOST_NAME/NORTHWND'
);
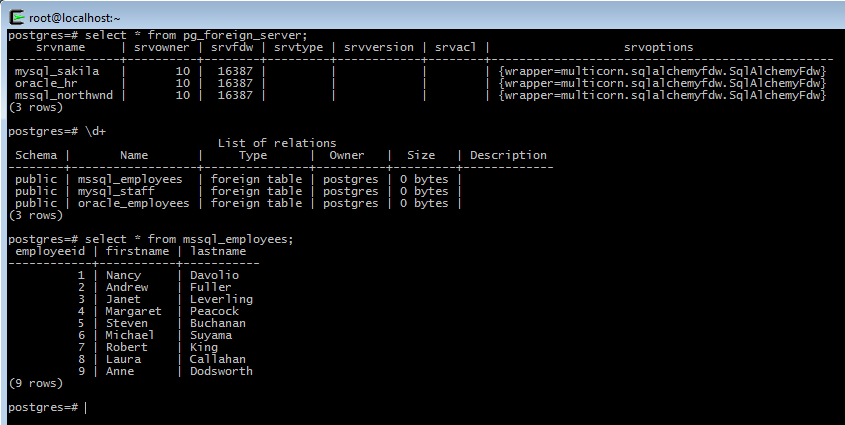
In Conclusion
Exposing a single database (Postgres) to apps and users, while accessing live data from 3 different backends behind the scenes is a very powerful approach. For example, we could expose this employee data in a single view using:
CREATE VIEW employees AS
SELECT staff_id as emp_id, first_name, last_name, 'MySQL' as source from mysql_staff
UNION ALL
SELECT employee_id as emp_id, first_name, last_name, 'Oracle' as source from oracle_employees
UNION ALL
SELECT EmployeeId as emp_id, FirstName as first_name, LastName as last_name, 'SQLServer' as source from mssql_employees;
Using Postgres FDW also opens up some more interesting possibilities including master data management, identity resolution and record de-duplication. I hope to cover these and more topics in future posts.
More in this series…
- Oracle into PostgreSQL with Talend
- SQL Server into PostgreSQL with SquirrelSQL
- MySQL into PostgreSQL with Python’s petl
- Excel into PostgreSQL with RapidMiner