Notes, for myself, installing on Ubuntu. I attempting to follow the excellent guide found in this LSTM tutorial by Vaibhaw Singh Chandel.
Tesseract 4.0
Currently in beta, Tesseract 4 seems to be a nice improvement upon version 3.
Install on Ubuntu 16.04
sudo add-apt-repository ppa:alex-p/tesseract-ocr
sudo apt-get update
sudo apt install tesseract-ocr tesseract-ocr-eng
sudo pip install pytesseract
Commandline
tesseract samples/inventory.png stdout -l eng --oem 1 --psm 3
Sample Python
Very simple example from great tutorial mentioned above.
import cv2
import sys
import pytesseract
if __name__ == '__main__':
if len(sys.argv) < 2:
print('Usage: python ocr_simple.py image.jpg')
sys.exit(1)
imPath = sys.argv[1]
config = ('-l eng --oem 1 --psm 3')
im = cv2.imread(imPath, cv2.IMREAD_COLOR)
text = pytesseract.image_to_string(im, config=config)
print(text)
OCR Results
First test with a fairly clear scan went well:
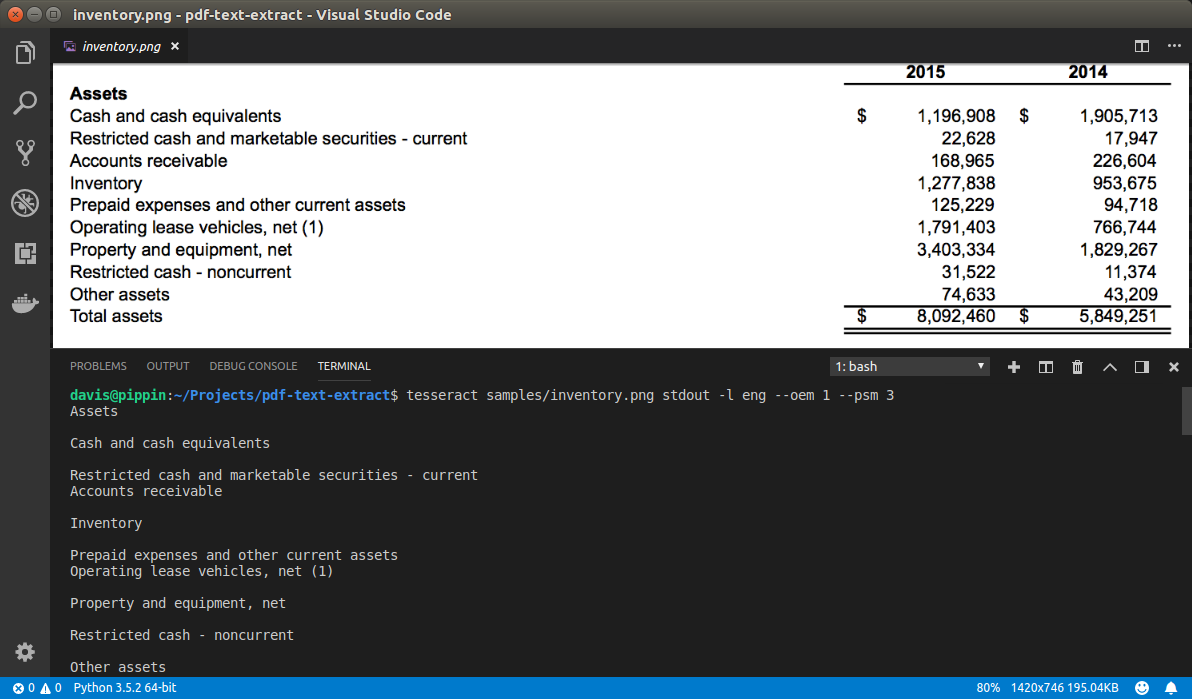
Second test with a much poorer scan had a lot more trouble:
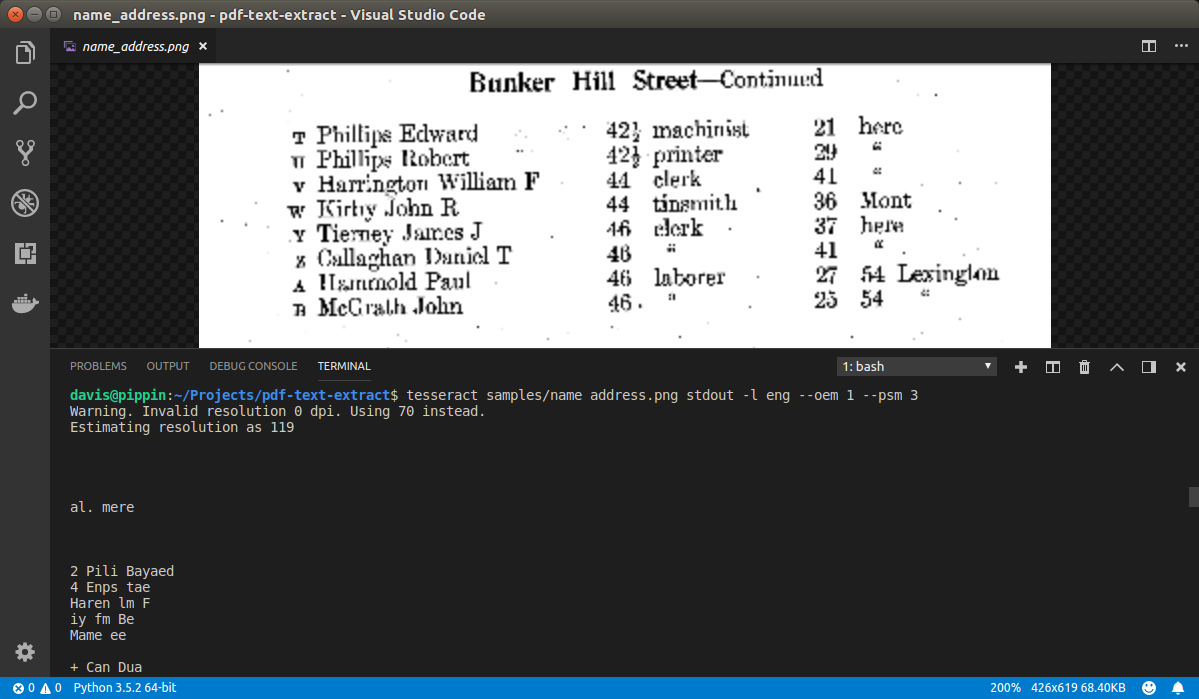
Conclusions
Overall, I’m quite impressed with the improvements made in Tesseract’s new LSTM mode. Definitely a worthwhile tool for those doing OCR these days.
More in this series…
- Optical Character Recognition - first attempt, investigating options.
- Tabular Data Extraction with GCV - further testing of Google Cloud Vision.