This covers my work on the fourth lesson of the Fast AI course.
Natural Language Processing (NLP)
The model used was initially trained on the Wikipedia test set (WT103). Very interesting to hear that what was state of the art last year, has been bundled into the base FastAI library this year. Fast-moving field…
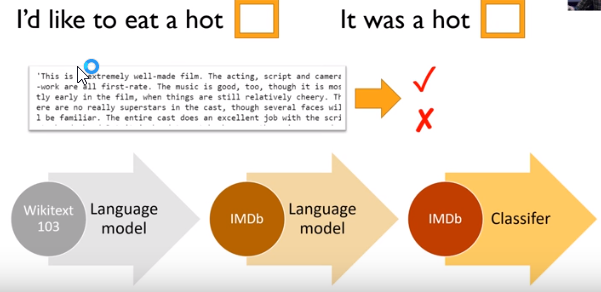
Steps involved:
- Train model on a large corpus of text, in this case the Wikipedia archive.
- Fine-tune the model on target corpus text, a training set in your particular domain.
- Remove the encoder in this fine tuned language model, and replace it with a classifier.
- Then fine-tune this model for the final classification task (in this case, sentiment analysis).
Takeaways
Obviously, one needs to stick to the same language between steps 1 and 2 above. Would be interesting to see how much the model fails if initially trained in English, then applied to Korean for example.
Interesting coverage of other types of data such as tabular (aka spreadsheet/database) and collaborative filtering as well.