I recently had an opportunity to research options for extracting tabular data from scanned PDF images. Turns out this a very challenging problem, given the widely varying layouts and scan quality of typical examples. I did find a very good approach by Markus Konrad that searched for table border lines using the same algorithm I recently used for finding road lane markers in dashcam footage. Here’s a sample input:
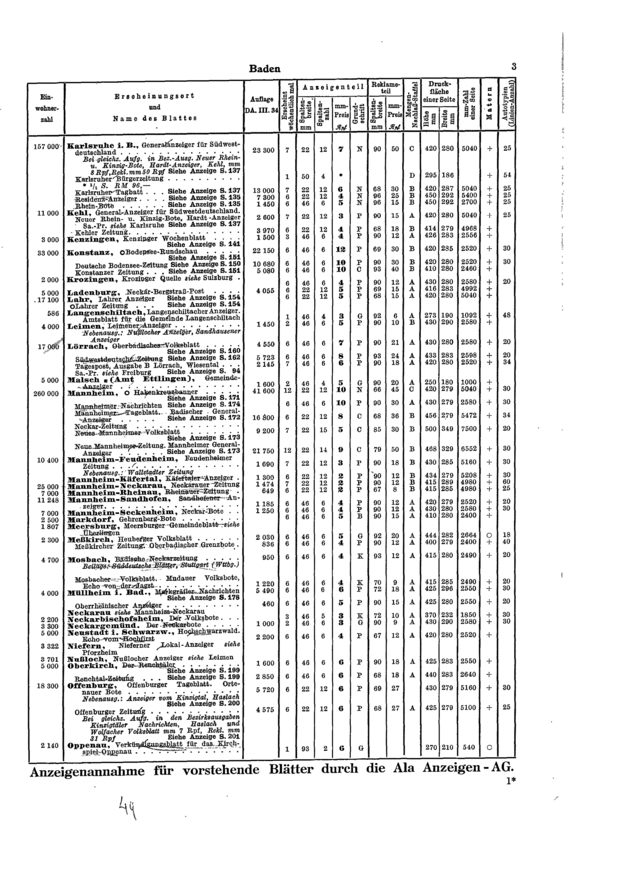
Clearly a challenge!
Optical Character Recognition
While the above example showed the importance of pre-processing the image before attempting OCR, I thought it would be interesting to attempt OCR with other options.
Tesseract
A good option on Linux is the venerable Tesseract project. Quickly installed on Ubuntu, I converted the PDF to PNG with ImageMagick, and then executed the Tesseract OCR:
sudo apt install tesseract-ocr
convert -density 300 samples/ALA1934_RR-excerpt.pdf -resize 25% samples/ALA1934_RR-excerpt.png
tesseract --tessdata-dir /usr/share/tesseract-ocr samples/ALA1934_RR-excerpt.png outputbase -l eng -psm 3
Unforunately, the output from default Tesseract on this sample was:
mum?” , w xm-Alt‘ynun4mmum4
...
Amman: rm- vmlahmae Blillcr dumb die Ala Anwigzn-AG.
,.
Hmm, not going to cut it…
Tesseract LSTM
Next up I tried the new alpha version of Tesseract that uses an LSTM neural networks for improved performance and quality of OCR. Unfortunately, in early 2018, I wasn’t able to make it work, however this looks like a promising avenue so I’ll be watching as Tesseract improves their implementation over time.
Google Cloud Vision
Next, I gave Google’s online API for image analysis, named Cloud Vision a try. Within a few seconds of uploading the PNG image, I was shown the following results:
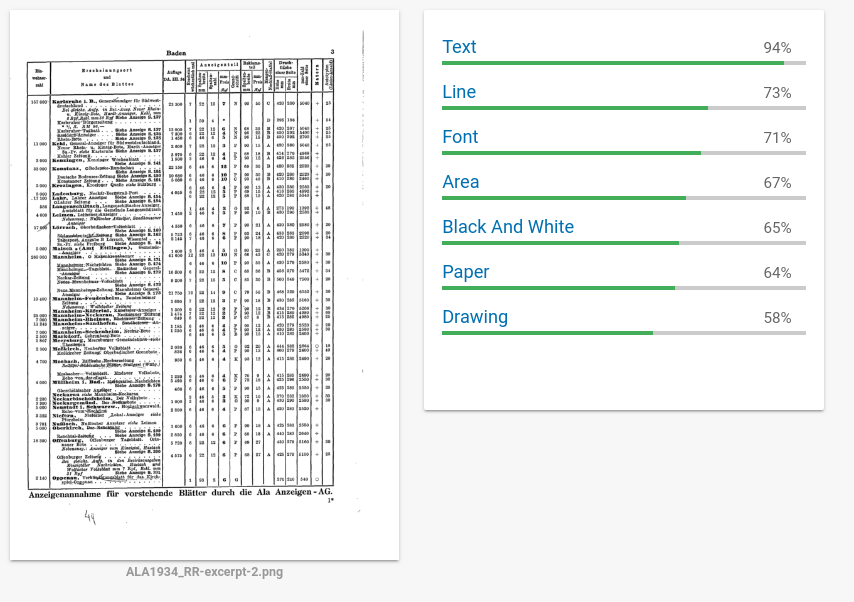
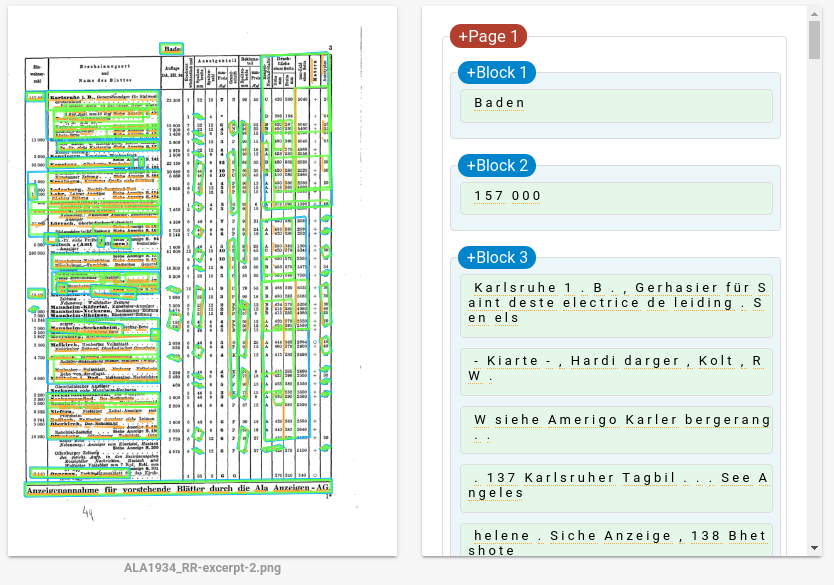
Conclusion
So for ‘off-the-shelf’ options Google Cloud Vision seems a promising alternative, though be mindful it is a commercial offering where one pays by the API call. I can definitely see that true tabular data extraction would require a multi-stage pipeline with manual review.
Next Steps
I’d like to try more test images with Google Cloud Vision to see how it performs overall. As well, I hope to revisit Tesseract LSTM as it moves to a full release.
More in this series…
- Tabular Data Extraction with GCV - further testing of Google Cloud Vision.